Code
flowchart LR D[D] -->|0.02| D1(D=1) D -->|0.98| D0(D=0) D1 -->|0.95| D1T1(T=1) D1 -->|0.05| D1T0(T=0) D0 -->|0.01| D0T1(T=1) D0 -->|0.99| D0T0(T=0)
Unit 2: Utility and Decision Theory

Vadim Sokolov
George Mason University
Spring 2025
How do people form probabilities or expectations in reality?
Psychologists have categorized many different biases that people have in their beliefs or judgments.
Loss Aversion
The most important finding of Kahneman and Tversky is that people are loss averse.
Utilities are defined over gains and losses rather than over final (or terminal) wealth, an idea first proposed by Markowitz. This is a violation of the EU postulates. Let \((x,y)\) denote a bet with gain \(x\) with probability \(y\).
To illustrate this subjects were asked:
In addition to whatever you own, you have been given $1000, now choose between the gambles \(A = ( 1000 , 0.5 )\) and \(B = ( 500 , 1 )\).
\(B\) was the more popular choice.
The same subjects were then asked: In addition to whatever you own, you have been given $2000, now choose between the gambles \(C = ( -1000 , 0.5 )\) and \(D = ( -500 , 1 )\).
This time \(C\) was more popular.
The key here is that their final wealth positions are identical yet people chose differently. The subjects are apparently focusing only on gains and losses.
When they are not given any information about prior winnings, they choose \(B\) over \(A\) and \(C\) over \(D\). Clearly for a risk averse people this is the rational choice.
Representativeness
When people try to determine the probability that evidence \(A\) was generated by model \(B\), they often use the representative heuristic. This means that they evaluate the probability by the degree to which \(A\) reflects the essential characteristics of \(B\).
Let \(P,Q\) be two probability distributions or risky gambles/lotteries.
\(p P + (1 - p ) Q\) is the compound or mixture lottery.
The rational agent (You) will have preferences between gambles.
\[ P \succeq Q \; \; \iff \; \; U (P) \geq U (Q ) \]
The two key facts then are uniqueness of probability and existence of expected utility. Formally,
This implies that \(U\) is additive and it is also unique up to affine transformation.
What are you willing to pay to enter the following game?
\[ \begin{aligned} E ( X) & = \sum_{T=1}^{\infty} 2^T 2^{-T} \\ & = 2 ( 1/2) + 4 (1/4) + 8(1/8) + \ldots \\ & = 1 + 1 + 1+ \ldots \rightarrow \infty \end{aligned} \] - Bernoulli (1754) constructed utility to value bets with \(E( u(X) )\).
Some examples of utility functions are,
Notice that after obtaining an expected utility value, you’ll have to find the corresponding reward/dollar amount.
Two gambles
Then we will compare the utility of those gambles
The solution depends on your risk preferences:
Risk neutral: a risk neutral person is indifferent about fair bets.
Linear Utility
Risk averse: a risk averse person prefers certainty over fair bets. \[ \mathbb{E}( U(X) ) < U \left ( \mathbb{E}(X) \right ) \; . \] Concave utility
Risk loving: a risk loving person prefer fair bets over certainty.
Depends on your preferences.
Probability is counter-intuitive!!!
Two urns
You have to make a choice between the following gambles
First compare the “Gambles”
| Experiment 1 | |||
|---|---|---|---|
| Gamble \(G_1\) | Gamble \(G_2\) | ||
| Win | Chance | Win | Chance |
| $25m | 0 | $25m | 0.1 |
| $5m | 1 | $5m | 0.89 |
| $0m | 0 | $0m | 0.01 |
| Experiment 2 | |||
|---|---|---|---|
| Gamble \(G_3\) | Gamble \(G_4\) | ||
| Win | Chance | Win | Chance |
| $25 | 0 | $25m | 0.1 |
| $5 | 0.11 | $5m | 0 |
| $0m | 0.89 | $0m | 0.9 |
If \(G_1 \geq G_2\) then \(G_3 \geq G_4\) and vice-versa.
Given (subjective) probabilities \(P = ( p_1 , p_2 , p_3 )\). Write \(E ( U | P )\) for expected utility. W.l.o.g. set \(u ( 0 ) = 0\) and for the high prize set \(u(\$25 \; {\rm million} ) = 1\). Which leaves one free parameter \(u = u (\$5 \; {\rm million} )\).
Power and log-utilities
\[ U_\gamma (W) = \frac{ W^{1-\gamma} -1 }{1-\gamma} \] - The special case \(U(W) = \log (W )\) for \(\gamma = 1\).
This leads to a myopic Kelly criterion rule.
Kelly Criterion corresponds to betting under binary uncertainty. - Consider a sequence of i.i.d. bets where
\[ p ( X_t = 1 ) = p \; \; {\rm and} \; \; p ( X_t = -1 ) = q=1-p \] The optimal allocation is \(\omega^\star = p - q = 2 p - 1\).
\[ \begin{aligned} \max_\omega \mathbb{E} \left ( \ln ( 1 + \omega W_T ) \right ) & = p \ln ( 1 + \omega ) + (1 -p) \ln (1 - \omega ) \\ & \leq p \ln p + q \ln q + \ln 2 \; {\rm and} \; \omega^\star = p - q \end{aligned} \]
\[ p ( X_t = 1 ) = p \; \; {\rm and} \; \; p ( X_t = -1 ) = q=1-p \] - Then the expected utility function is
\[ p \ln ( 1 + b \omega ) + (1 -p) \ln (1 - a \omega ) \] - The optimal solution is
\[ \omega^\star = \frac{bp - a q}{ab} = \frac{p-q}{\sigma} \]
Two possible market opportunities: one where it offers you \(4/1\) when you have personal odds of \(3/1\) and a second one when it offers you \(12/1\) while you think the odds are \(9/1\).
In expected return these two scenarios are identical both offering a 33% gain.
In terms of maximizing long-run growth, however, they are not identical.
| Market | You | \(p\) | \(\omega^\star\) |
|---|---|---|---|
| \(4/1\) | \(3/1\) | \(1/4\) | \(1/16\) |
| \(12/1\) | \(9/1\) | \(1/10\) | \(1/40\) |
\[ \frac{ (1/4) \times 4 - (3/4) }{4} = \frac{1}{16} \; {\rm and} \; \frac{ (1/10) \times 12 - (9/10) }{12} = \frac{1}{40} \]
Two losing bets can be combined to a winner

Two Losing Bets+Volatility


Kelly Criterion: Optimal wager in binary setting \[ \omega^\star = \frac{p \cdot O -q }{O} \]
Merton’s Rule: in continuous setting is Kelly \[ \omega^\star = \frac{1}{\gamma} \frac{\mu}{\sigma^2} \]
Consider logarithmic utility (CRRA with \(\gamma=1\)). This is a pure Kelly rule.
The fractional Kelly rule leads to a more realistic allocation.


Optimal Bayes Rebalancing


Immediately after you have win, you should feel a little regret!
Claiming racehorse whose value is uncertain
| Value | Outcome |
|---|---|
| 0 | horse never wins |
| 50,000 | horse improves |
Simple expected value tells you \[ E(X) = \frac{1}{2} \cdot 0 + \frac{1}{2} \cdot 50,000 = \$25,000. \] In a $20,000 claiming race (you can buy the horse for this fixed fee ahead of time from the owner) it looks like a simple decision to claim the horse.
Asymmetric information!
Suppose that a dealer pays $20K for a car and wants to sell for $25K, a lemon is only worth $5K.
Let’s first suppose only 10% of cars are lemons, the customer’s calculations are \[ E (X)= \frac{9}{10} \cdot 25 + \frac{1}{10} \cdot 5 = \$ 23 K \]
Dealer is missing $2000. Therefore, they should try and persuade the customer its not a lemon by offering a warranty for example.
Again what should the dealer do?
flowchart LR D[D] -->|0.02| D1(D=1) D -->|0.98| D0(D=0) D1 -->|0.95| D1T1(T=1) D1 -->|0.05| D1T0(T=0) D0 -->|0.01| D0T1(T=1) D0 -->|0.99| D0T0(T=0)
Imagine that the above story takes place in a small town, with \(1,000\) people.
Prior: 20 people, are sick, and 980 are healthy.
Aminister the test to everyone: 19 of the 20 sick people test positive, 9.8 of the healthy people test positive, we round it to 10.
Now if the doctor sends everyone who tests positive to the national hospital, there will be 10 healthy and 19 sick patients. 1 to 2 ratio or 66 percent of the patients are healthy.
| A/S | \(a_T\) | \(a_N\) |
|---|---|---|
| \(D_0\) | 90 | 100 |
| \(D_1\) | 90 | 0 |
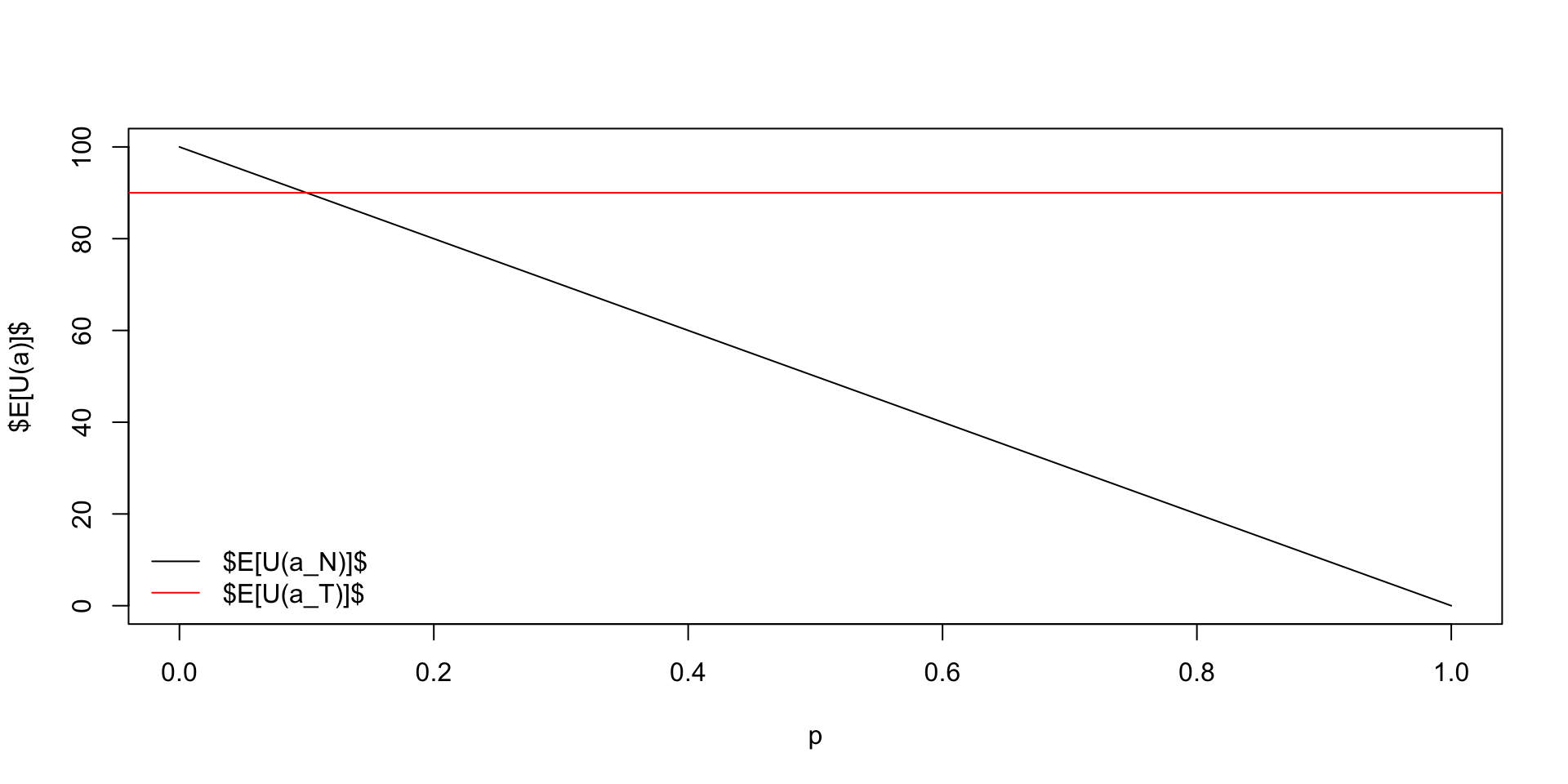
Then expected (unconditional) utility of the treatment is 90 and no treatment is 98. A huge difference. Given our prior knowledge, we should not treat everyone.
How does the utility will change when our probability of disease changes?
Expected utility of the treatment and no treatment as a function of the prior probability of disease.
The crossover point is. \[ 100(1-p) = 90, ~p = 0.1 \]
The gap of of \(0.9-100(1-p)\) is the expected gain from treatment.
We will need to calculate the posterior probabilities
[1] 0.001029654[1] 99.89703[1] 90Given test is negative, our best action is not to treat. Our utility is 100. What if the test is positive?
[1] 0.6597222[1] 34.02778[1] 90The best option is to treat now! Given the test our strategy is to treat if the test is positive and not treat if the test is negative.
Let’s calculate the expected utility of this strategy.
[1] 0.0288[1] 0.9712[1] 99.612The utility of out strategy of 100 is above of the strategy prior to testing (98), this difference of 2 is called the value of information.
Two players \(A\) and \(B\) have both a red and a blue marble. They present one marble to each other. The payoff table is as follows:
The tit-for-tat strategy, where you cooperate until your opponent defects. Then you match his last response.
Nash equilibrium will also allow us to study the concept of a randomized strategy (ie. picking a choice with a certain probability) which turns out to be optimal in many game theory problems.
First, assume that the players have a \(\frac{1}{2}\) probability of playing Red or Blue. Thus each player has the same expected payoff \(E(A) = 1\) \[\begin{align*} E(A) &= \frac{1}{4} \cdot 3 + \frac{1}{4} \cdot 1 =1 \\ E(B) &= \frac{1}{4} \cdot 2 + \frac{1}{4} \cdot 2 =1 \end{align*}\]
We might go one step further and look at the risk (and measured by a standard deviation) and calculate the variances of each players payout \[\begin{align*} Var (A) & = (1-1)^2 \cdot \frac{1}{4} +(3-1)^2 \cdot \frac{1}{4} + (0-1)^2 \cdot \frac{1}{2} = 1.5 \\ Var(B) & = 1^2 \cdot \frac{1}{2} + (2-1)^2 \cdot \frac{1}{2} = 1 \end{align*}\] Therefore, under this scenario, if you are risk averse, player \(B\) position is favored.
The matrix of probabilities with equally likely choices is given by
| \(A,B\) | Probability |
|---|---|
| \(P( red, red )\) | (1/2)(1/2)=1/4 |
| \(P( red, blue )\) | (1/2)(1/2)=1/4 |
| \(P( blue, red )\) | (1/2)(1/2)=1/4 |
| \(P( blue, blue )\) | (1/2)(1/2)=1/4 |
Now they is no reason to assume ahead of time that the players will decide to play \(50/50\). We will show that there’s a mixed strategy (randomized) that is a Nash equilibrium that is, both players won’t deviate from the strategy.
We’ll prove that the following equilibrium happens:
In this case the expected payoff to playing Red equals that of playing Blue for each player. We can simply calculate: \(A\)’s expected payoff is 3/4 and \(B\)’s is $1 \[ E(A) = \frac{1}{8} \cdot 3 + \frac{3}{8} \cdot 1 = \frac{3}{4} \] Moreover, \(E(B) =1\), thus \(E(B) > E(A)\). We see that \(B\) is the favored position. It is simple that if I know that you are going to play this strategy and vice-versa, neither of us will deviate from this strategy – hence the Nash equilibrium concept.
Nash equilibrium probabilities are: \(p=P( A \; red )= 1/2, p_1 = P( B \; red ) = 1/4\) with payout matrix
| \(A,B\) | Probability |
|---|---|
| \(P( red, red )\) | (1/2)(1/4)=1/8 |
| \(P( red, blue )\) | (1/2)(3/4)=3/8 |
| \(P( blue, red )\) | (1/2)(1/4)=1/8 |
| \(P( blue, blue )\) | (1/2)(3/4)=3/8 |
We have general payoff probabilities: \(p=P( A \; red ), p_1 = P( B \; red )\)
\[\begin{align*} f_A ( p , p_1 ) =& 3 p p_1 + ( 1 -p ) ( 1 - p_1 ) \\ f_B ( p , p_1 ) =& 2 \{ p(1 - p_1) + ( 1 -p ) p_1 \} \end{align*}\]
To find the equilibrium point \[\begin{align*} ( \partial / \partial p ) f_A ( p , p_1 ) =& 3 p_1 - ( 1 - p_1 ) = 4 p_1 -1 \; \; \mathrm{so} \; \; p_1= 1/4 \\ ( \partial / \partial p_1 ) f_B ( p , p_1 ) =& 2 ( 1 - 2p ) \; \; \mathrm{so} \; \; p= 1/2 \end{align*}\]
Much research has been directed to repeated games versus the one-shot game and is too large a topic to discuss further.
What are the drawbacks of the equilibrium analysis?