graph TB
R((Color)) --> F((Fruit))
RR((Shape)) --> F
D((Size)) --> F
3 Bayes Rule
When the facts change, I change my mind. What do you do, sir? John Maynard Keynes
One of the key questions in the theory of learning is: How do you update your beliefs in the presence of new information? Bayes rule provides the answer. Conditional probability can be interpreted as updating your probability of event \(A\) after you have learned the new information that \(B\) has occurred. In the sense probability is also the language of how you’ll change options in the light of new evidence. For example, we need to find probability that a thrown dice shows on its upper surface an odd number and we found out that number shown is less then 4. We write \(p(A=\text{odd} \mid B = \text{less then 4})= 2/3\).
Probability rules allow us to change our mind if the facts change. For example, suppose that \(B = \{ B_1 , B_2 \}\) consists of two pieces of information and that we are interested in \(P(A\mid B_1,B_2)\). Bayes rule simply lets you calculate this conditional probability in a sequential fashion. First, conditioning on the information contained in \(B_1\), let’s us calculate \[ P( A| B_1 ) = \frac{ p( B_1 \mid A ) P( A) }{ P( B_1 ) } \] Then, using the posterior probability \(P( A| B_1 )\) as the “new” prior for the next piece of information \(B_2\) lets us find \[ P( A| B_1 , B_2 ) = \frac{ p( B_2 \mid B_1 , A ) P( A \mid B_1 ) }{ P( B_2 \mid B_1 ) } \] Hence, we see that we need assessments of the two conditional probabilities \(P( B_1 \mid A )\) and \(P( B_2 \mid B_1 , A )\). In many situations, the latter will be simply \(P( B_2 \mid A )\) and not involve \(B_1\). The events \(( B_1, B_2 )\) will be said to be conditionally independent given \(A\).
This concept generalizes to a sequence of events where \(B = \{ B_1,\ldots B_n \}\). When learning from data will will use this property all the time. An illustrative example will be the Black Swan problem which we discuss later.
Bayes’ rule is a fundamental concept in probability theory and statistics. It describes how to update our beliefs about an event based on new evidence. We start with an initial belief about the probability of an event (called the prior probability). We then observe some conditional information information (e.g. evidence). We use Bayes’ rule to update our initial belief based on the evidence, resulting in a new belief called the posterior probability. Remember, the formula is \[ P(A\mid B) = \dfrac{P(B\mid A) P(A)}{P(B)} \] where:
The ability to use Bayes rule sequentially is a key in many applications, when we need to update our beliefs in the presence of new information. For examples, Bayesian learning was used by mathematician Alan Turing in England in Bletchley Park to break the German Enigma code - a development that helped the Allies win the Second World War (Simpson 2010). Turing called his algorithm Banburismus, it is a process he invented which used sequential conditional probability to infer information about the likely settings of the Enigma machine.
Dennis Lindley argued that we should all be trained Bayes rule and conditional probability can be simply view as disciplined probability accounting. Akin to how market odds change as evidence changes. One issue is human behavior and intuition trained in how to use Bayes rule, akin to learning the Alphabet!
Example 3.1 (Intuition) Out intuition is not well trained to make use of a Bayes rule. If I tell you that Steve was selected at random from a representative sample. He is an 6 foot 2 and an excellent basketball player. He goes to gym every day and practices hard playing basketball. Do you think Steve is a custodian at a factory or an NBA player? Most people assume Steve is an NBA player which is wrong. The ration of NBA players to custodians is very small, probabilistically Steve is more likely to be an NBA player. Let’s look at it graphically. The key us to provide the right conditioning and to consider the prior probability! Even though the ratio of people who people who practice basketball hard is much hither among NBA players (it is 1) when compared to custodians, larger number of population means we still have more custodians in the US then NBA players.
\[\begin{align*} \prob{\text{Practice hard} \mid \text{Play in NBA}} \approx 1\\ \prob{ \text{Play in NBA} \mid \text{Practice hard}} \approx 0. \end{align*}\]
Even though you practice hard, the odds of playing in NBA are low (\(1000\) players out of \(7\) billion). But given you’re in NBA, you no doubt practice very hard. To understand this further, lets look at the conditional probability implication and apply Bayes rule \[ p \left ( \text{Play in NBA} \mid \text{Practice hard} \right ) = \dfrac{p \left ( \text{Practice hard} \mid \text{Play in NBA} \right )p( \text{Play in NBA})}{p(\text{Practice hard})}. \] The initial (a.k.a. prior) probability \(p(\text{Play in NBA} ) = \frac{1000}{7 \cdot 10^6} \approx 0\), makes the conditional (or, so called, posterior) probability also very small. \[ p \left ( \text{Play in NBA} \mid \text{Practice hard} \right ) \approx 0, \] \(P(\text{practice hard})\) is not that small and \(P(\text{practice hard} \mid \text{play in NBA})=1\). Hence, when one ‘vevevses the conditioning’ one gets a very small probability. This makes sense!
3.1 Law of Total Probability
The Law of Total Probability is a fundamental rule relating marginal probabilities to conditional probabilities. It’s particularly useful when you’re dealing with a set of mutually exclusive and collectively exhaustive events.
Suppose you have a set of events \(B_1, B_2, ..., B_n\) that are mutually exclusive (i.e., no two events can occur at the same time) and collectively exhaustive (i.e., at least one of the events must occur). The Law of Total Probability states that for any other event \(A\), the probability of \(A\) occurring can be calculated as the sum of the probabilities of \(A\) occurring given each \(B_i\), multiplied by the probability of each \(B_i\) occurring.
Mathematically, it is expressed as:
\[ P(A) = \sum_{i=1}^{n} P(A\mid B_i) P(B_i) \]
Example 3.2 (Total Probability) Let’s consider a simple example to illustrate this. Suppose you have two bags of balls. Bag 1 contains 3 red and 7 blue balls, while Bag 2 contains 6 red and 4 blue balls. You randomly choose one of the bags and then randomly draw a ball from that bag. What is the probability of drawing a red ball?
Here, the events \(B_1\) and \(B_2\) can be choosing Bag 1 and Bag 2, respectively. You want to find the probability of event \(A\) (drawing a red ball).
Applying the law:
- \(P(A|B_1)\) is the probability of drawing a red ball from Bag 1, which is \(\frac{3}{10}\).
- \(P(A|B_2)\) is the probability of drawing a red ball from Bag 2, which is \(\frac{6}{10}\).
- Assume the probability of choosing either bag is equal, so \(P(B_1) = P(B_2) = \frac{1}{2}\).
Using the Law of Total Probability:
\[ P(A) = P(A|B_1) \times P(B_1) + P(A|B_2) \times P(B_2)= \frac{3}{10} \times \frac{1}{2} + \frac{6}{10} \times \frac{1}{2} = \frac{9}{20} \]
So, the probability of drawing a red ball in this scenario is \(\frac{9}{20}\).
This law is particularly useful in complex probability problems where direct calculation of probability is difficult. By breaking down the problem into conditional probabilities based on relevant events, it simplifies the calculation and helps to derive a solution.
Example 3.3 (Craps) Craps is a fast-moving dice game with a complex betting layout. It’s highly volatile, but eventually your bankroll will drift towards zero. Lets look at the pass line bet. The expectation \(E(X)\) governs the long run. When 7 or 11 comes up, you win. When 2,3 or 12 comes up, this is known as “craps”, you lose. When 4,5,6,8,9 or 10 comes up, this number is called the “point”, the bettor continues to roll until a 7 (you lose) or the point comes up (you win).
We need to know the probability of winning. The pay-out, probability and expectation for a $1 bet
| Win | Prob |
|---|---|
| 1 | 0.4929 |
| -1 | 0.5071 |
This leads to an edge in favor of the house as \[ E(X) = 1 \cdot 0.4929 + (- 1) \cdot 0.5071 = -0.014 \] The house has a 1.4% edge.
To calculate the probability of winning: \(P( W )\) let’s use the law of total probability \[ P( W ) = \sum_{ \mathrm{Point} } P ( W \mid \mathrm{Point} ) P ( \mathrm{Point} ) \] The set of \(P( \mathrm{Point} )\) are given by
| Value | Probability | Percentage |
|---|---|---|
| 2 | 1/36 | 2.78% |
| 3 | 2/36 | 5.56% |
| 4 | 3/36 | 8.33% |
| 5 | 4/36 | 11.1% |
| 6 | 5/36 | 13.9% |
| 7 | 6/36 | 16.7% |
| 8 | 5/36 | 13.9% |
| 9 | 4/36 | 11.1% |
| 10 | 3/36 | 8.33% |
| 11 | 2/36 | 5.56% |
| 12 | 1/36 | 2.78% |
The conditional probabilities \(P( W \mid \mathrm{Point} )\) are harder to calculate \[ P( W \mid 7 \; \mathrm{or} \; 11 ) = 1 \; \; \mathrm{and} \; \; P( W \mid 2 , 3 \; \mathrm{or} \; 12 ) = 0 \] We still have to work out all the probabilities of winning given the point. Suppose the point is \(4\) \[ P( W \mid 4 ) = P ( 4 \; \mathrm{before} \; 7 ) = \dfrac{P(4)}{P(7)+P(4)} = \frac{3}{9} = \frac{1}{3} \] There are 6 ways of getting a 7, 3 ways of getting a 4 for a total of 9 possibilities. Now do all of them and sum them up. You get \[ P( W) = 0.4929 \]
3.2 Independence
Historically, the concept of independence in experiments and random variables has been a defining mathematical characteristic that has uniquely shaped the theory of probability. This concept has been instrumental in distinguishing the theory of probability from other mathematical theories.
Using the notion of conditional probability, we can define independence of two variables. Two random variable \(X\) and \(Y\) are said to be independent if \[ \prob{Y = y \mid X = x} = \prob{Y = y}, \] for all possible \(x\) and \(y\) values. That is, learning information \(X=x\) doesn’t affect.
Conditional probabilities are counter intuitive. For example, one of the most important properties is typically \(p( x \mid y ) \neq p( y\mid x )\), our probabilistic assessment of \(Y\) for any value \(y\). This is known as Prosecutors’ Fallacy as it arises when probability is used as evidence in a court of law. In the case of independence, \(p(x \mid y) = p(x)\) and \(p(y \mid x) = p(y)\). Specifically, the probability of innocence given the evidence is not the same as the probability of evidence given innocence. It is very important to ask the question “what exactly are we conditioning on?” Usually, the observed evidence or data. Probability, of course, given evidence was one of the first applications of Bayes. Central to personalized probability. Clearly this is a strong condition and rarely holds in practice.
We just derived an important relation, that allows us to calculate conditional probability \(p(x \mid y)\) when we know joint probability \(p(x,y)\) and marginal probability \(p(y)\). The total probability or evidence can be calculated as usual, via \(p(y) = \sum_{x}p(x,y)\).
We will see that independence will lead to a different conclusion that the Bayes conditional probability decomposition: specifically, independence yields \(p( x,y ) = p(x) p(y)\) and Bayes says \(p(x ,y) = p(x)p(x \mid y)\).
We need to specify distribution on each of those variables. Two random variable \(X\) and \(Y\) are independent if \[ \prob{Y = y \mid X = x} = \prob{Y = y}, \] for all possible \(x\) and \(y\) values variables separately The joint distribution will be giving by \[ p(x,y) = p(x)p(y). \] If \(X\) and \(Y\) are independent then probability of the event \(X\) and event \(Y\) happening at the same time is the product of individual probabilities. From the conditional distribution formula it follows that \[ p(x \mid y) = \dfrac{p(x,y)}{p(y)} = \dfrac{p(x)p(y)}{p(y)} = p(x). \] Another way to think of independence is to say that knowing the value of \(Y\) doesn’t tell us anything about possible values of \(X\). For example when tossing a coin twice, the probability of getting \(H\) in the second toss does not depend on the outcome of the first toss.
The expression of independence expresses the fact that knowing \(X=x\) tells you nothing about \(Y\). In the coin tossing example, if \(X\) is the outcome of the first toss and \(Y\) is the outcome of the second toss \[ \prob{ X=H \mid Y=T } = \prob{X=H \mid Y=H } = \prob{X=H}. \]
Let’s do a similar example which illustrates this point clearly. Most people would agree with the following conditional probability assessments
3.3 Naive Bayes
Use of the Bayes rule allows us to build our first predictive model, called Naive Bayes classifier. Naive Bayes is a collection of classification algorithms based on Bayes Theorem. It is not a single algorithm but a family of algorithms that all share a common principle, that every feature being classified is independent of the value of any other feature. For example, a fruit may be considered to be an apple if it is red, round, and about 3” in diameter. A Naive Bayes classifier considers each of these “features” (red, round, 3” in diameter) to contribute independently to the probability that the fruit is an apple, regardless of any correlations between features. Features, however, aren’t always independent which is often seen as a shortcoming of the Naive Bayes algorithm and this is why it’s labeled “naive”.
Although it’s a relatively simple idea, Naive Bayes can often outperform other more sophisticated algorithms and is extremely useful in common applications like spam detection and document classification. In a nutshell, the algorithm allows us to predict a class, given a set of features using probability. So in another fruit example, we could predict whether a fruit is an apple, orange or banana (class) based on its colour, shape etc (features). In summary, the advantages are:
- It’s relatively simple to understand and build
- It’s easily trained, even with a small dataset
- It’s fast!
- It’s not sensitive to irrelevant features
The main disadvantage is that it assumes every feature is independent, which isn’t always the case.
Let’s say we have data on 1000 pieces of fruit. The fruit being a Banana, Orange or some Other fruit and imagine we know 3 features of each fruit, whether it’s long or not, sweet or not and yellow or not, as displayed in the table below:
| Fruit | Long | Sweet | Yellow | Total |
|---|---|---|---|---|
| Banana | 400 | 350 | 450 | 500 |
| Orange | 0 | 150 | 300 | 300 |
| Other | 100 | 150 | 50 | 200 |
| Total | 500 | 650 | 800 | 1000 |
From this data we can calculate marginal probabilities
- 50% of the fruits are bananas
- 30% are oranges
- 20% are other fruits
Based on our training set we can also say the following:
- From 500 bananas 400 (0.8) are Long, 350 (0.7) are Sweet and 450 (0.9) are Yellow
- Out of 300 oranges 0 are Long, 150 (0.5) are Sweet and 300 (1) are Yellow
- From the remaining 200 fruits, 100 (0.5) are Long, 150 (0.75) are Sweet and 50 (0.25) are Yellow So let’s say we’re given the features of a piece of fruit and we need to predict the class. If we’re told that the additional fruit is Long, Sweet and Yellow, we can classify it using the following formula and subbing in the values for each outcome, whether it’s a Banana, an Orange or Other Fruit. The one with the highest probability (score) being the winner.
Give the evidence \(E\) (\(L\) = Long, \(S\) = Sweet and \(Y\) = Yellow) we can calculate the probability of each class \(C\) (\(B\) = Banana, \(O\) = Orange or \(F\) = Other Fruit) using Bayes’ Theorem: \[\begin{align*} P(B \mid E) = & \frac{P(L \mid B)P(S \mid B)P(Y \mid B)P(B)}{P(L)P(S)P(Y)}\\ =&\frac{0.8\times 0.7\times 0.9\times 0.5}{P(E)}=\frac{0.252}{P(E)} \end{align*}\]
Orange: \[ P(O\mid E)=0. \]
Other Fruit: \[\begin{align*} P(F \mid E) & = \frac{P(L \mid F)P(S \mid F)P(Y \mid F)P(F)}{P(L)P(S)P(Y)}\\ =&\frac{0.5\times 0.75\times 0.25\times 0.2}{P(E)}=\frac{0.01875}{P(E)} \end{align*}\]
In this case, based on the higher score, we can assume this Long, Sweet and Yellow fruit is, in fact, a Banana.
Now that we’ve seen a basic example of Naive Bayes in action, you can easily see how it can be applied to Text Classification problems such as spam detection, sentiment analysis and categorization. By looking at documents as a set of words, which would represent features, and labels (e.g. “spam” and “ham” in case of spam detection) as classes we can start to classify documents and text automatically.
Example 3.4 (Spam Filtering) Original spam filtering algorithm was based on Naive Bayes.The “naive” aspect of Naive Bayes comes from the assumption that inputs (words in the case of text classification) are conditionally independent, given the class label. Naive Bayes treats each word independently, and the model doesn’t capture the sequential or structural information inherent in the language. It does not consider grammatical relationships or syntactic structures. The algorithm doesn’t understand the grammatical rules that dictate how words should be combined to form meaningful sentences. Further, it doesn’t understand the context in which words appear. For example, it may treat the word “bank” the same whether it refers to a financial institution or the side of a river bank. Despite its simplicity and the naive assumption, Naive Bayes often performs well in practice, especially in text classification tasks.
We start by collecting a dataset of emails labeled as “spam” or “not spam” (ham) and calculate the prior probabilities of spam (\(P(\text{spam})\)) and not spam (\(P(\text{ham})\)) based on the training dataset, by simply counting the proportions of each in the data.
Then each email gets converted into a bag-of-words representation (ignoring word order and considering only word frequencies). Then, we create a vocabulary of unique words from the entire dataset \(w_1,w_2,\ldots,w_N\) and calculate conditional probabilities \[ P(\mathrm{word}_i \mid \text{spam}) = \frac{\text{Number of spam emails containing }\mathrm{word}_i}{\text{Total number of spam emails}}, ~ i=1,\ldots,n \] \[ P(\mathrm{word}_i \mid \text{ham}) = \frac{\text{Number of ham emails containing }\mathrm{word}_i}{\text{Total number of ham emails}}, ~ i=1,\ldots,n \]
Now, we are ready to use our model to classify new emails. We do it by calculating the posterior probability using Bayes’ theorem. Say email has a set of \(k\) words \(\text{email} = \{w_{e1},w_{e2},\ldots, w_{ek}\}\), then \[ P(\text{spam} \mid \text{email}) = \frac{P(\text{email} \mid \text{spam}) \times P(\text{spam})}{P(\text{email})} \] Here \[ P(\text{email} \mid \text{spam}) = P( w_{e1} \mid \text{spam})P( w_{e2} \mid \text{spam})\ldots P( w_{ek} \mid \text{spam}) \] We calculate \(P(\text{spam} \mid \text{email})\) is a similar way.
Finally, we classify the email as spam or ham based on the class with the highest posterior probability.
Suppose you have a spam email with the word “discount” appearing. Using Naive Bayes, you’d calculate the probability that an email containing “discount” is spam (\(P(\text{spam} \mid \text{discount})\)) and ham (\(P(\text{ham} \mid \text{discount})\)), and then compare these probabilities to make a classification decision.
While the naive assumption simplifies the model and makes it computationally efficient, it comes at the cost of a more nuanced understanding of language. More sophisticated models, such as transformers, have been developed to address these limitations by considering the sequential nature of language and capturing contextual relationships between words.
In summary, naive Bayes, due to its simplicity and the naive assumption of independence, is not capable of understanding the rules of grammar, the order of words, or the intricate context in which words are used. It is a basic algorithm suitable for certain tasks but may lack the complexity needed for tasks that require a deeper understanding of language structure and semantics.
3.4 Real World Bayes
Example 3.5 (Apple Watch Series 4 ECG and Bayes’ Theorem) The Apple Watch Series 4 can perform a single-lead ECG and detect atrial fibrillation. The software can correctly identify 98% of cases of atrial fibrillation (true positives) and 99% of cases of non-atrial fibrillation (true negatives).
| Predicted | atrial fibrillation | no atrial fibrillation | Total |
|---|---|---|---|
| atrial fibrillation | 1960 | 980 | 2940 |
| no atrial fibrillation | 40 | 97020 | 97060 |
| Total | 2000 | 98000 | 100000 |
However, what is the probability of a person having atrial fibrillation when atrial fibrillation is identified by the Apple Watch Series 4? We use Bayes theorem to answer this question. \[ p(\text{atrial fibrillation}\mid \text{atrial fibrillation is identified }) = \frac{0.01960}{ 0.02940} = 0.6667 \]
The conditional probability of having atrial fibrillation when the Apple Watch Series 4 detects atrial fibrillation is about 67%.
In people younger than 55, Apple Watch’s positive predictive value is just 19.6 percent. That means in this group – which constitutes more than 90 percent of users of wearable devices like the Apple Watch – the app incorrectly diagnoses atrial fibrillation 79.4 percent of the time. (You can try the calculation yourself using this Bayesian calculator: enter 0.001 for prevalence, 0.98 for sensitivity, and 0.996 for specificity).
The electrocardiogram app becomes more reliable in older individuals: The positive predictive value is 76 percent among users between the ages of 60 and 64, 91 percent among those aged 70 to 74, and 96 percent for those older than 85.
In the case of medical diagnostics, the sensitivity is the ratio of people who have disease and tested positive to the total number of positive cases in the population \[ p(T=1\mid D=1) = \dfrac{p(T=1,D=1)}{p(D=1)} = 0.019/0.002 = 0.95 \] The specificity is given by \[ p(T=0\mid D=0) = \dfrac{p(T=0,D=0)}{p(D=0)} = 0.9702/0.98 = 0.99. \] As we see the test is highly sensitive and specific. However, only 66% of those who are tested positive will have a disease. This is due to the fact that number of sick people is much less then the number of healthy and presence of type I error.
Example 3.6 (Google random clicker) Google provides a service where they ask visitors to your website ato answer a single survey question before they get access to the content on the page. Among all of the users, there are two categories
- Random Clicker (RC)
- Truthful Clicker (TC)
There are two possible answers to the survey: yes and no. Random clickers would click either one with equal probability. You are also giving the infor- mation that the expected fraction of random clickers is 0.3. After a trial period, you get the following survey results: 65% said Yes and 35% said No.
The qustion is How many people people who are truthful clickers answered yes \(P(Y\mid TC)\)?
We are given \(P(Y\mid RC) = P(N\mid RC) = 0.5\), \(P(RC)= 0.3\) and \(P(Y)\) = 0.65
The totla probability is \[ P(Y) = P(Y\mid RC)P(RC) + P(Y\mid TC)P(TC) = 0.65, \] Thus \[ P(Y\mid TC) = (P(Y) - P(Y\mid RC)P(RC))/P(TC) = (0.65-0.5\cdot 0.3)/0.7 = 0.71 \]
Example 3.7 (USS Scorpion sank 5 June, 1968 in the middle of the Atlantic.) Experts placed bets of each casualty and how each would affect the sinking. Undersea soundings gave a prior on location. Bayes rule: \(L\) is location and \(S\) is scenario \[ p (L \mid S) = \frac{ p(S \mid L) p(L)}{p(S)} \] The Navy spent \(5\) months looking and found nothing. Build a probability map: within \(5\) days, the submarine was found within \(220\) yards of most likely probability!
A similar story happened during the search of an Air France plane that flew from Rio to Paris.
Example 3.8 (Wald and Airplane Safety) Many lives were saved by analysis of conditional probabilities performed by Abraham Wald during the Second World War. He was analyzing damages on the US planes that came back from bombarding missions in Germany. Somebody suggested to analyze distribution of the hits over different parts of the plane. The idea was to find a pattern in the damages and design a reinforcement strategy.
After examining hundreds of damaged airplanes, researchers came up with the following table
| Location | Number of Planes |
|---|---|
| Engine | 53 |
| Cockpit | 65 |
| Fuel system | 96 |
| Wings, fuselage, etc. | 434 |
We can convert those counts to probabilities
| Location | Number of Planes |
|---|---|
| Engine | 0.08 |
| Cockpit | 0.1 |
| Fuel system | 0.15 |
| Wings, fuselage, etc. | 0.67 |
We can conclude the the most likely area to be damaged on the returned planes was the wings and fuselage. \[ \prob{\mbox{hit on wings or fuselage } \mid \mbox{returns safely}} = 0.67 \] Wald realized that analyzing damages only on survived planes is not the right approach. Instead, he suggested that it is essential to calculate the inverse probability \[ \prob{\mbox{returns safely} \mid \mbox{hit on wings or fuselage }} = ? \] To calculate that, he interviewed many engineers and pilots, he performed a lot field experiments. He analyzed likely attack angles. He studied the properties of a shrapnel cloud from a flak gun. He suggested to the army that they fire thousands of dummy bullets at a plane sitting on the tarmac. Wald constructed a ‘probability model’ careful to reconstruct an estimate for the joint probabilities. Table below shows the results.
| Hit | Returned | Shut Down |
|---|---|---|
| Engine | 53 | 57 |
| Cockpit | 65 | 46 |
| Fuel system | 96 | 16 |
| Wings, fuselage, etc. | 434 | 33 |
Which allows us to estimate joint probabilities, for example \[ \prob{\mbox{outcome = returns safely} , \mbox{hit = engine }} = 53/800 = 0.066 \] We also can calculate the conditional probabilities now \[ \prob{\mbox{outcome = returns safely} \mid \mbox{hit = wings or fuselage }} = \dfrac{434}{434+33} = 0.93. \] Should we reinforce wings or fuselage? Which part of the airplane does need ot be reinforced? \[ \prob{\mbox{outcome = returns safely} \mid \mbox{hit = engine }} = \dfrac{53}{53+57} = 0.48 \] Here is another illustration taken from Economics literature. This insight led to George Akerlof winning the Nobel Prize for the concept of asymmetric information.
Example 3.9 (Coin Jar) Large jar containing 1024 fair coins and one two-headed coin. You pick one at random and flip it \(10\) times and get all heads. What’s the probability that the coin is the two-headed coin? The probability of initially picking the two headed coin is 1/1025. There is 1/1024 chance of of getting \(10\) heads in a row from a fair coin. Therefore, it’s a \(50/50\) bet.
Let’s do the formal Bayes rule math. Let \(E\) be the event that you get \(10\) Heads in a row, then
\[ P \left ( \mathrm{two \; headed} \mid E \right ) = \frac{ P \left ( E \mid \mathrm{ two \; headed} \right )P \left ( \mathrm{ two \; headed} \right )} {P \left ( E \mid \mathrm{ fair} \right )P \left ( \mathrm{ fair} \right ) + P \left ( E \mid \mathrm{ two \; headed} \right )P \left ( \mathrm{ two \; headed} \right )} \] Therefore, the posterior probability \[ P \left ( \mathrm{ two \; headed} \mid E \right ) = \frac{ 1 \times \frac{1}{1025} }{ \frac{1}{1024} \times \frac{1024}{1025} + 1 \times \frac{1}{1025} } = 0.50 \] What’s the probability that the next toss is a head? Using the law of total probability gives
\[\begin{align*} P( H ) &= P( H \mid \mathrm{ two \; headed} )P( \mathrm{ two \; headed} \mid E ) + P( H \mid \mathrm{ fair} )P( \mathrm{ fair} \mid E) \\ & = 1 \times \frac{1}{2} + \frac{1}{2} \times \frac{1}{2} = \frac{3}{4} \end{align*}\]
Example 3.10 (Monty Hall Problem) Another example of a situation when calculating probabilities is counterintuitive. The Monte Hall problems was named after the host of the long-running TV show Let’s make a Deal. The original solution was proposed by Marilyn vos Savant, who had a column with the correct answer that many Mathematicians thought was wrong!
The game set-up is as follows. A contestant is given the choice of 3 doors. There is a prize (a car, say) behind one of the doors and something worthless behind the other two doors: two goats. The game is as follows:
- You pick a door.
- Monty then opens one of the other two doors, revealing a goat. He can’t open your door or show you a car
- You have the choice of switching doors.
The question is, is it advantageous to switch? The answer is yes. The probability of winning if you switch is 2/3 and if you don’t switch is 1/3.
Conditional probabilities allow us to answer this question. Assume you pick door 2 (event \(A\)) at random, given that the host opened Door 3 and showed a goat (event B), we need to calculate \(P(A\mid B)\). The prior probability that the car is behind Door 2 is \(P(A) = 1/3\) and \(P(B\mid A) = 1\), if the car is behind Door 2, the host has no choice but to open Door 3. The Bayes rule then gives us \[ P(A\mid B) = \frac{P(B\mid A)P(A)}{P(B)} = \frac{1/3}{1/2} = \frac{2}{3}. \] The overall probability of the host opening Door 3 \[ P(B) = (1/3 \times 1/2) + (1/3 \times 1) = 1/6 + 1/3 = 1/2. \]
The posterior probability that the car is behind Door 2 after the host opens Door 3 is 2/3. It is to your advantage to switch doors.
Example 3.11 (Prosecutors Fallacy) The Prosecutor’s Fallacy is a logical error that occurs when a prosecutor presents evidence or statistical data in a way that suggests a defendant’s guilt, even though the evidence is not as conclusive as it may seem. This fallacy arises from a misunderstanding or misrepresentation of conditional probabilities and not understanding that that \[ P(E\mid G) \ne P(G\mid E) \]
It involves confusion between the probability of two events: the probability of the evidence \(E\), given the defendant’s guilt (which is what the prosecutor may be presenting), and the probability of the defendant’s guilt \(G\), given the evidence (which is what is often of more interest in a trial).
Here’s a simplified example to illustrate the Prosecutor’s Fallacy. Suppose a crime has been committed, and DNA evidence is found at the crime scene. The prosecutor claims that the probability of finding this particular DNA at the scene, given the defendant’s innocence, is very low (making the evidence seem incriminating). However, the Prosecutor’s Fallacy occurs when the prosecutor incorrectly assumes that this low probability implies a low probability of the defendant’s innocence. In reality, the probability of the DNA being found at the crime scene (given the defendant’s innocence) might also be low if the DNA is relatively rare but not exclusive to the defendant.
The fallacy often arises from a failure to consider the base rate or prior probability of the event being investigated. To avoid the Prosecutor’s Fallacy, it’s crucial to carefully distinguish between the probability of the evidence given the hypothesis (guilt or innocence) and the probability of the hypothesis given the evidence.
Consider a more concrete example of base rate fallacy. Say we have a witness who is 80% certain she saw a “checker” (\(C\)) taxi in the accident. We need to calculate \(P(C\mid E)\). Assiming the base rate of 20% \(P(C) = 0.2\), we get \[ P(C\mid E) = \dfrac{P(E\mid C)P(C)}{P(E)} = \dfrac{0.8\cdot 0.2}{0.8\cdot 0.2 + 0.2\cdot 0.8} = 0.5 \] The witness identification accuracy \(P(C\mid E) = 0.8\) is called the sensitivity.
Even with a highly accurate witness, the probability that the identified taxi is a Checker will be less than 80%, reflecting the impact of the base rate. Ignoring the base rate can lead to a significant overestimation of the probability of the identified event.
Example 3.12 (Law Example)
Suppose you’re serving on a jury in the city of New York, with a population of roughly 10 million people. A man stands before you accused of murder, and you are asked to judge whether he is guilty \(G\) or not guilty \(\bar G\). In his opening remarks, the prosecutor tells you that the defendant has been arrested on the strength of a single, overwhelming piece of evidence: that his DNA matched a sample of DNA taken from the scene of the crime. Let’s denote this evidence by the letter \(D\). To convince you of the strength of this evidence, the prosecutor calls a forensic scientist to the stand, who testifies that the probability that an innocent person’s DNA would match the sample found at the crime scene is only one in a million. The prosecution then rests its case. Would you vote to convict this man? If you answered “yes,” you might want to reconsider! You are charged with assessing \(P(G \mid D)\)—that is, the probability that the defendant is guilty, given the information that his DNA matched the sample taken from the scene. Bayes’ rule tells us that \[ P(G\mid D)= P(G)P(D\mid G)/P(D), ~ P(D) = P(D \mid G)P(G) + P(D \mid \bar G)P(\bar G) \] We know the following quantities:
- The prior probability of guilt, \(P(G)\), is about one in 10 million. New York City has 10 million people, and one of them committed the crime.
- The probability of a false match, \(P(D \mid \bar G)\), is one in a million, because the forensic scientist tested to this fact.
To use Bayes’ rule, let’s make one additional assumption: that the likelihood, \(P(D\mid G)\), is equal to 1. This means we’re assuming that, if the accused were guilty, there is a 100% chance of seeing a positive result from the DNA test. Let’s plug these numbers into Bayes’ rule and see what we get: \[ P(G\mid D) = 0.09 \] The probability of guilt looks to be only 9%! This result seems shocking in light of the forensic scientist’s claim that \(P(D \mid \bar G)\) is so small: a “one in a million chance” of a positive match for an innocent person. Yet the prior probability of guilt is very low \(P(G)\) is a mere one in 10 million—and so even very strong evidence still only gets us up to \(P(G | D) = 0.09\).
Conflating \(P(\bar G \mid D)\) with \(P(D \mid \bar G)\) is a serious error in probabilistic reasoning. These two numbers are typically very different from one another, because conditional probabilities aren’t symmetric. As we’ve said more than once, \(P(\text{practices hard} \mid \text{plays in NBA}) \approx 1\), while \(P(\text{plays in NBA} \mid \text{practices hard}) \approx 0\). An alternate way of thinking about this result is the following. Of the 10 million innocent people in New York, ten would have DNA matches merely by chance. The one guilty person would also have a DNA match. Hence there are 11 people with a DNA match, only one of whom is guilty, and so \(P(G \mid D) \approx 1/11\). Your intuition may mislead, but Bayes’ rule never does!
Example 3.13 (Island Problem) There are \(N+1\) people on the island and one is a criminal. We have probability of a trait of a criminal equal to \(p\), which is \(p = P(E\mid I)\), the probability of evidence, given innocence. Then we have a suspect who is matching the trait and we need to find probability of being guilty, given the evidence \(P(G \mid E)\). It is easier to do the Bayes rule in the odds form. There are three components to the calculations: the prior odds of innocence, \[ O ( I ) = P (G) / P ( I ), \] the Bayes factor, \[ \frac{P(E\mid G)}{P(E\mid I)}. \] and the posterior odds of innocence. \[ O(I\mid E) = \dfrac{P(G\mid E)}{P(I\mid E)} = \dfrac{1}{Np}. \]
The Cromwell’s rule states that the use of prior probability of 1 or 0 should be avoided except when it is known for certain that the probability is 1 or 0. It is named after Oliver Cromwell who wrote to the General Assembly of he Church of Scotland in 1650 “I beseech you, in the bowels of Christ, it is possible that you may be mistaken”. In other words, using the Bayes rule \[ P(G\mid E) = \dfrac{P(E\mid G)}{P(E)}P(G), \] if \(P(G)\) is zero, it does not matter what the evidence is. Symmetrically, probability of innocence is zero if the evidence is certain. In other words, if \(P(E\mid I) = 0\), then \(P(I\mid E) = 0\). This is a very strong statement. It is not always true, but it is a good rule of thumb, it is a good way to avoid the prosecutor’s fallacy.
Example 3.14 (Nakamura’s Alleged Cheating) In our paper Maharaj, Polson, and Sokolov (2023), we provide a statistical analysis of the recent controversy between Vladimir Kramnik (ex-world champion) and Hikaru Nakamura . Kramnik called into question Nakamura’s 45.5 out of 46 win streak in a 3+0 online blitz contest at chess.com. In this example we reproduce this paper and assess the weight of evidence using an a priori probabilistic assessment of Viswanathan Anand and the streak evidence of Kramnik. Our analysis shows that Nakamura has 99.6 percent chance of not cheating given Anand’s prior assumptions.
We start by addressing the argument of Kramnik which is based on the fact that the probability of such a streak is very small. This falls into precisely the Prosecutor’s Fallacy. Let introduce the notations. We denote by \(G\) the event of being guilty and \(I\) the event of innocence. We use \(E\) to denote evidence. In our case the evidence is the streak of wins by Nakamura. The Kramnik’s argument is that probability of observing the streak is very low, thus we might have a case of cheating. This is the prosecutor’s fallacy \[ P(I \mid E) \neq P(E \mid I). \] Kramnik’s calculations neglects other relevant factors, such as the prior probability of the cheating. The prosecutor’s fallacy can lead to an overestimation of the strength of the evidence and may result in an unjust conviction. In the cheating problem, at the top level of chess prior probability of \(P(G)\) is small! According to a recent statement by Viswanathan Anand, the probability of cheating is \(1/10000\).

Given the prior ratio of cheaters to not cheaters is \(1/N\), meaning out of \(N+1\) players, there is one cheater, the Bayes calculations requires two main terms. The first one is the prior odds of guilt: \[ O ( G ) = P (I) / P ( G ). \] Here \(P(I)\) and \(P(G)\) are the prior probabilities of innocence and guilt respectively.
The second term is the Bayes factor, which is the ratio of the probability of the evidence under the guilt hypothesis to the probability of the evidence under the innocence hypothesis. The Bayes factor is given by \[ L(E\mid G) = \frac{P(E\mid I)}{P(E\mid G)}. \]
Product of the Bayes factor and the prior odds is the posterior odds of guilt, given the evidence. The posterior odds of guilt is given by \[ O(G\mid E) = O(G) \times L(E\mid G). \]
The odds of guilty is \[ O ( G ) = \dfrac{N/(N+1)}{1/(N+1)} = N. \]
The Bayes factor is given by \[ \frac{P(E\mid I)}{P(E\mid G)} = \dfrac{p}{1} = p. \] Thus, the posterior odds of guilt are \[ O(G\mid E) = Np. \] There are two numbers we need to estimate to calculate the odds of cheating given the evidence, namely the prior probability of cheating given via \(N\) and the probability of a streak \(p = P(E\mid I)\).
There are multiple ways to calculate the probability of a streak. We can use the binomial distribution, the negative binomial distribution, or the Poisson distribution. The binomial distribution is the most natural choice. The probability of a streak of \(k\) wins in a row is given by \[ P(E\mid I) = \binom{N}{k} q^k (1-q)^{N-k}. \] Here \(q\) is is the probability of winning a single game. Thus, for a streak of 45 wins in a row, we have \(k = 45\) and \(N = 46\). We encode the outcome of a game as \(1\) for a win and \(0\) for a loss or a draw. The probability of a win is \(q = 0.8916\) (Nakamura’s Estimate, he reported on his YouTube channel). The probability of a streak is then 0.029. The individual game win probability is calculated from the ELO rating difference between the players.
The ELO rating of Hikaru is 3300 and the average ELO rating of his opponents is 2950, according to Kramnik. The difference of 350 corresponds to the odds of winning of \(wo = 10^{350/400} = 10^{0.875} = 7.2\). The probability of winning a single game is \(q = wo/(1+wo) = 0.8916\).
Then we use the Anand’s prior of \(N = 10000\) to get the posterior odds of cheating given the evidence of a streak of 45 wins in a row. The posterior odds of being innocent are 285. The probability of cheating is then \[ P(G\mid E) = 1/(1+O(G\mid E)) = 0.003491. \] Therefore the probability of innocent \[ P(I\mid E) = \frac{Np}{Np+1} = 0.9965. \]
For completeness, we perform sensitivity analysis and also get the odds of not cheating for \(N = 500\), which should be high prior probability given the status of the player and the importance of the event. We get \[ P(I\mid E) = \frac{Np}{Np+1} = 0.9445. \]
There are several assumptions we made in this analysis.
- Instead of calculating game-by-game probability of winning, we used the average probability of winning of 0.8916, provided by Nakamura himself. This is a reasonable assumption given the fact that Nakamura is a much stronger player than his opponents. This assumption slightly shifts posterior odds in favor of not cheating. Due to Jensen inequality, we have \(E(q^{50}) > E(q)^{50}\). Expected value of the probability of winning a single game is \(E(q) = 0.8916\) and the expected value of the probability of a streak of 50 wins is \(E(q^{50})\). We consider the difference between the two to be small. Further, there is some correlation between the games, which also shifts the posterior odds in favor of not cheating. For example, some players are on tilt. Given they lost first game, they are more likely to lose the second game.
- There are many ways to win 3+0 unlike in classical chess. For example, one can win on time. We argue that probability of winning calculated from the ELO rating difference is underestimated.
Next, we can use the Bayes analysis to solve an inverse problem and to find what prior you need to assume and how long of a sequence you need to observe to get 0.99 posterior? Small sample size, we have \(p\) close to 1. Figure 3.1 shows the combination of prior (\(N\)) and the probability of a streak (\(p\)) that gives posterior odds of 0.99.
Indeed, the results of the Bayesian analysis contradict the results of a traditional p-value based approach. A p-value is a measure used in frequentist statistical hypothesis testing. It represents the probability of obtaining the observed results, or results more extreme, assuming that the null hypothesis is true. The null hypothesis is a default position that Nakamura is not cheating and we compare the ELO-based expected win probability of \(q=0.8916\) to the observed on of \(s=45/46=0.978\). Under the null hypothesis, Nakamura should perform at the level predicted by \(q\).
q = 0.8916
p = dbinom(45,46,q)
N = 10000
odds = p*N
print(1-1/(1+odds)) 1print(1/(1+odds)) 0.0035print(N*p/(N*p+1)) 1p = seq(from=0.006, to=0.07, length.out=500)
N = seq(500,10000, by=250)
plot(99/N,N,xlab="p", ylab="N", type='l', lwd=3, col="blue")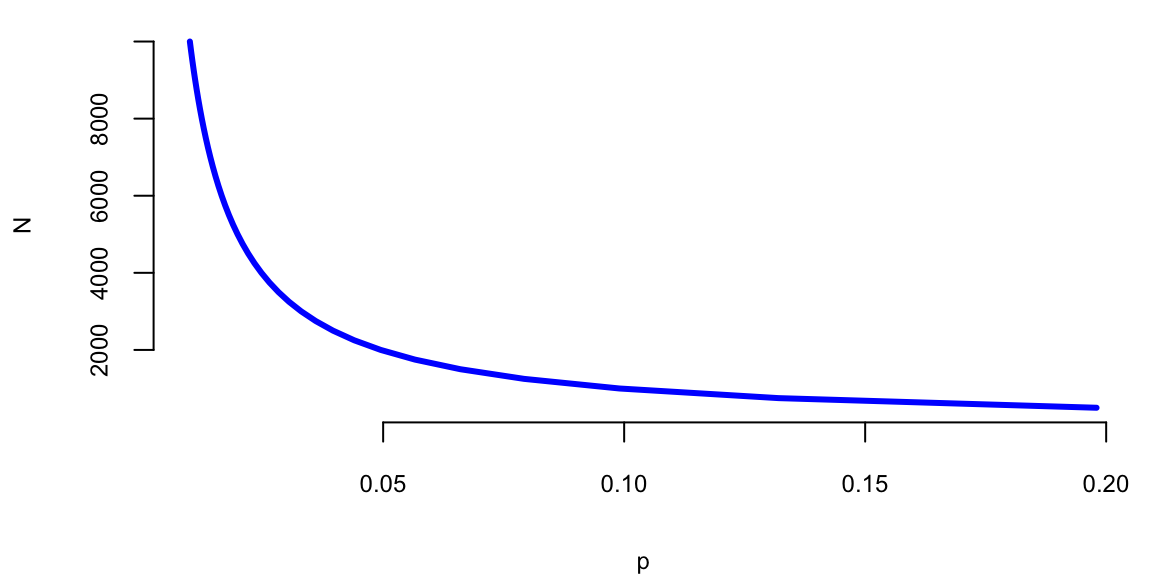
Example 3.15 (Sally Clark Case: Independence or Bayes Rule?) To show that independence can lead to dramatically different results from Bayes conditional probabilities, consider the Sally Clark case. Sally Clark was accused and convicted of killing her two children who could have both died of SIDS. One explanation is that this was a random occurrence, the other one is that they both died of sudden infant death syndrome (SIDS). How can we use conditional probability to figure out a reasonable assessment of the probability that she murdered her children. First, some known probability assessments
- The chance of a family of non-smokers having a SIDS death is \(1\) in \(8,500\).
- The chance of a second SIDS death is \(1\) in \(100\).
- The chance of a mother killing her two children is around \(1\) in \(1,000,000\).
Under Bayes \[\begin{align*} \prob{\mathrm{both} \; \; \mathrm{SIDS}} & = \prob{\mathrm{first} \; \mathrm{SIDS}} \prob{\mathrm{Second} \; \;\mathrm{SIDS} \mid \mathrm{first} \; \mathrm{SIDS}}\\ & = \frac{1}{8500} \cdot \frac{1}{100} = \frac{1}{850,000}. \end{align*}\]
The \(1/100\) comes from taking into account the genetics properties of SIDS. Independence, as implemented by the court, gets you to a probabilistic assessment of \[ P \left( \mathrm{both} \; \; \mathrm{SIDS} \right) = (1/8500) (1/8500) = (1/73,000,000). \] This is a low probability. It is still not the answer to our question of context. We need a conditional probability, this will come to the Bayes rule.
First, some general comment on the likelihood ratio calculation used to assess the weight of evidence in favor of guilty v.s. innocent evidence. Under Bayes we’ll find that there’s reasonable evidence that she’d be acquitted. We need the relative odds ratio. Let \(I\) denote the event that Sally Clark is innocent and \(G\) denotes guilty. Let \(E\) denote the evidence. In most cases, \(E\) contains a sequence \(E_1, E_2, \ldots\) of ‘facts’ and we have to use the likelihood ratios in turn. Bayes rule then tells you to combine via multiplicative fashion. If likelihood ratio \(>1\), odds of guilty. If likelihood ratio \(<1\), more likelihood to be \(I\). By Bayes rule \[ \frac{p(I\mid E)}{p(G\mid E)} = \frac{p( E\text{ and } I)}{p( G, I)}. \] If we further decompose \(p(E \text{ and } I) = p(E\mid I )p(I)\) then we have to discuss the prior probability of innocence, namely \(p(I)\). Hence this is one subtle advantage of the above decomposition.
The underlying intuition that Bayes gives us in this example, is that one the two possible explanations of the data, both of which are unlikely, it is the relative likelihood of comparison that should matter. Here is a case where the \(p\)-value would be non-sensible (\(p(E\mid I) \neq p(I\mid E)\)). Effectively comparing two rare event probabilities from the two possible models or explanations.
Hence putting these two together gives the odds of guilt as \[ \frac{p(I\mid E)}{p(G\mid E)} = \frac{1/850,000}{1/1,000,000} = 1.15. \] Solving for the posterior probability yields \(46.5\%\) for probability of guilty given evidence. \[ p( G\mid E) = \frac{1}{1 + O(G\mid E)} = 0.465. \] Basically a \(50/50\) bet. Not enough to definitively convict! But remember that our initial prior probability on guilt \(p(G)\) was \(10^{-6}\). So now there has been a dramatic increase to a posterior probability of \(0.465\). So it’s not as if Bayes rule thinks this is evidence in the suspects favor – but the magnitude is still not in the \(0.999\) range though, where most jurors would have to be to feel comfortable with a guilt verdict.
If you use the “wrong” model of independence (as the court did) you get \[ P \left( \mathrm{both} \; \; \mathrm{SIDS} \right) = \frac{1}{8500} \cdot\frac{1}{8500} = \frac{1}{73,000,000}. \] With the independence assumption, you make the assessment \[ \frac{p(I\mid E)}{p(G\mid E)} = \frac{1}{73} \; \mathrm{ and} \; p( G\mid E) \approx 0.99. \] Given these probability assumptions, the suspect looks guilty with probability 99%.
Experts also mis-interpret the evidence by saying: 1 in 73 million chance that it is someone else. This is clearly false and misleading to the jury and has leads to appeals.
Example 3.16 (O. J. Simpson Case (Dershowitz Fallacy))
This example is based on I. J. Good’s, “When batterer turns murderer.” Nature, 15 June 1995, p. 541. Alan Dershowitz, on the O. J. Simpson defense team, stated on T.V. and in newspapers that only 0.004 percent of men who abuse their wives go on to murder them. He clearly wanted his audience to interpret this to mean that the evidence of abuse by Simpson would only suggest a 1 in 2500 chance of his being guilty of murdering her. He used probability to argue that because so few husbands who batter their wifes actually go on to murder their wives. Thus, O.J. is highly likely to be not guilty. This leaves out the most relevant conditioning information that we also know that Nicole Brown Simpson was actually murdered. Both authors believe the jury would be more interested in the probability that the husband is guilty of the murder of his wife given that he abused his wife and his wife was murdered. They both solve this problem by using Bayes’ theorem.
In this example, the notation \(B\) represents “woman battered by her husband, boyfriend, or lover”, \(M\) represents the event “woman murdered”, and by extension, \(M, B\) denotes “woman murdered by her batterer”. Our goal is to show that \[ P(M,B \mid M) \neq P(M,B \mid B). \]
It is not hard to come to a wrong conclusion if you don’t take into account all the relevant conditional information. He intended this information to exonerate O.J. In 1992. the women population of the US was 125 million and 4936 women were murdered, thus \[ P(M) = 4936/125,000,000 = 0.00004 = 1/25,000. \] At the same year about 3.5 million women were battered \[ P(B) = 2.5/125 = 0.028. \] That same year 1432 women were murdered by their previous batterers, so the marginal probability of that event is \(P(M, B) = 1432/125,000,000 = 0.00001 = 1/87,290\), and the conditional probability, \(P(M, B | B)\) is 1432 divided by 3.5 million, or \(1/2444\). These are the numbers Dershowitz used to obtain his estimate that about 1 in 2500 battered women go on to be murdered by their batterers.
We need to calculate \[ P(M,B \mid M) = P(M | M,B) P(M,B) / P(M). \] We know \(P(M | M,B) = 1\) and \(P(M,B) / P(M) = 0.000 01/0.000 04 = 0.29\), or about 1 in 3.5.
Alan Dershowitz provided the jury with an accurate but irrelevant probability. A murdered woman having been murdered by her batterer is 709 times more likely than a battered woman being murdered by her batterer: \[ P(M,B\mid M)\approx 709\times P(M,B\mid B). \]
The argument used by Dershowitz relating to the Simpson case has been discussed by John Paulos in an op-ed article in the Philadelphia Inquirer (15 Oct. 1995, C7) and his book “Once Upon a Number”, by I.J. Good in an article in Nature (June 15,1995, p 541) and by Jon Merz and Jonathan Caulkins in an article in Chance Magazine, (Spring 1995, p 14).
Probability measures the uncertainty of an event. But how do we measure probability? One school of thought, takes probability as subjective, namely personal to the observer. de Finetti famously concluded that “Probability does not exist.” Measuring that is personal to the observer. It’s not like mass which is a property of an object. If two different observers have differing “news” then there is an them to bet (exchange contracts). Thus leading to a assessment of probability. Ramsey (1926) takes this view.
Much of data science is then the art of building probability models to study phenomenon. For many events most people will agree on their probabilities, for example \(p(H) = 0.5\) and \(p(T) = 0.5\). In the subjective view of probability we can measure or elicit a personal probability as a “willingness to play”. Namely, will you be willing to bet $1 so you can get $2 if head lands Tail and $0 if Head occurs? For more details, see Chapter 4.
3.5 Graphical Representation of Probability and Conditional Independence.
We can use the telescoping property of conditional probabilities to write the joint probability distribution as a product of conditional probabilities. This is the essence of the chain rule of probability. It is given by \[ p(x_1, x_2, \ldots, x_n) = p(x_1)p(x_2 \mid x_1)p(x_3 \mid x_1, x_2) \ldots p(x_n \mid x_1, x_2, \ldots, x_{n-1}). \] The expression on the right hand side can be simplified if some of the variables are conditionally independent. For example, if \(x_3\) is conditionally independent of \(x_2\), given \(x_1\), then we can write \[ p(x_3 \mid x_1, x_2) =p(x_3 \mid x_1). \]
In a high-dimensional case, when we have a joint distribution over a large number of random variables, we can often simplify the expression by using independence or conditional independence assumptions. Sometimes it is convenient to represent these assumptions in a graphical form. This is the idea behind the concept of a Bayesian network. Essentially, graph is a compact representation of a set of independencies that hold in the distribution.
Let’s consider an example of joint distribution with three random variables, we have the following joint distribution: \[ p(a,b,c) = p(a\mid b,c)p(b\mid c)p(c) \]
When two nodes are connected they are not independent. Consider the following three cases:

\[ p(b\mid c,a) = p(b\mid c),~ p(a,b,c) = p(a)p(c\mid a)p(b\mid c) \]

\[ p(a\mid b,c) = p(a\mid c), ~ p(a,b,c) = p(a\mid c)p(b\mid c)p(c) \]

\[ p(a\mid b) = p(a),~ p(a,b,c) = p(c\mid a,b)p(a)p(b) \]
Although the graph shows us the conditional independence assumptions, we can also derive other independencies from the graph An interesting question if they are connected through a third node. In the first case (a), we have \(a\) and \(b\) connected through \(c\). Thus, \(a\) can influence \(b\). However, once \(c\) is known, \(a\) and \(b\) are independent. In case (b) the logic here is similar, \(a\) can influence \(b\) through \(c\), but once \(c\) is known, \(a\) and \(b\) are independent. In the third case (c), \(a\) and \(b\) are independent, but once \(c\) is known, \(a\) and \(b\) are not independent. You can formally derive these independencies from the graph by comparing \(p(a,b\mid c)\) and \(p(a\mid c)p(b\mid c)\).
Example 3.17 (Bayes Home Diagnostics) Suppose that a house alarm system sends me a text notification when some motion inside my house is detected. It detect motion when I have a person inside (burglar) or during an earthquake. Say, from prior data we know that during an earthquake alarm is triggered in 10% of the cases. One I receive a text message, I start driving back home. While driving I hear on the radio about a small earthquake in our area. Now we want to know \(p(b \mid a)\) and \(p(b \mid a,r)\). Here \(b\) = burglary, \(e\) = earthquake, \(a\) = alarm, and \(r\) = radio message about small earthquake.
The joint distribution is then given by \[ p(b,e,a,r) = p(r \mid a,b,e)p(a \mid b,e)p(b\mid e)p(e). \] Since we know the causal relations, we can simplify this expression \[ p(b,e,a,r) = p(r \mid e)p(a \mid b,e)p(b)p(e). \] The joint distribution is defined by
| \(p(a=1 \mid b,e)\) | b | e |
|---|---|---|
| 0 | 0 | 0 |
| 0.1 | 0 | 1 |
| 1 | 1 | 0 |
| 1 | 1 | 1 |
Graphically, we can represent the relations between the variables known as a Directed Acyclic Graph (DAG), which is known as Bayesian network.’
graph TB
b((b)) --> a((a))
e((e)) --> a
e --> r((r))
Now we can easily calculate \(p(a=0 \mid b,e)\), from the property of a probability distribution \(p(a=1 \mid b,e) + p(a=0 \mid b,e) = 1\). In addition, we are given \(p(r=1 \mid e=1) = 0.5\) and \(p(r=1 \mid e=0) = 0\). Further, based on historic data we have \(p(b) = 2\cdot10^{-4}\) and \(p(e) = 10^{-2}\). Note that causal relations allowed us to have a more compact representation of the joint probability distribution. The original naive representations requires specifying \(2^4\) parameters.
To answer our original question, calculate \[ p(b \mid a) = \dfrac{p(a \mid b)p(b)}{p(a)},~~p(b) = p(a=1 \mid b=1)p(b=1) + p(a=1 \mid b=0)p(b=0). \] We have everything but \(p(a \mid b)\). This is obtained by marginalizing \(p(a=1 \mid b,e)\), to yield \[ p(a \mid b) = p(a \mid b,e=1)p(e=1) + p(a \mid b,e=0)p(e=0). \] We can calculate \[ p(a=1 \mid b=1) = 1, ~p(a=1 \mid b=0) = 0.1*10^{-2} + 0 = 10^{-3}. \] This leads to \(p(b \mid a) = 2\cdot10^{-4}/(2\cdot10^{-4} + 10^{-3}(1-2\cdot10^{-4})) = 1/6\).
This result is somewhat counterintuitive. We get such a low probability of burglary because its prior is very low compared to prior probability of an earthquake. What will happen to posterior if we live in an area with higher crime rates, say \(p(b) = 10^{-3}\). Figure 3.3 shows the relationship between the prior and posterior. \[ p(a \mid b) = \dfrac{p(b)}{p(b) + 10^{-3}(1-p(b))} \]
prior <- seq(0, .1, length.out = 200)
post <- prior / (prior + 0.001 * (1 - prior))
plot(prior, post, type = "l", lwd = 3, col = "red")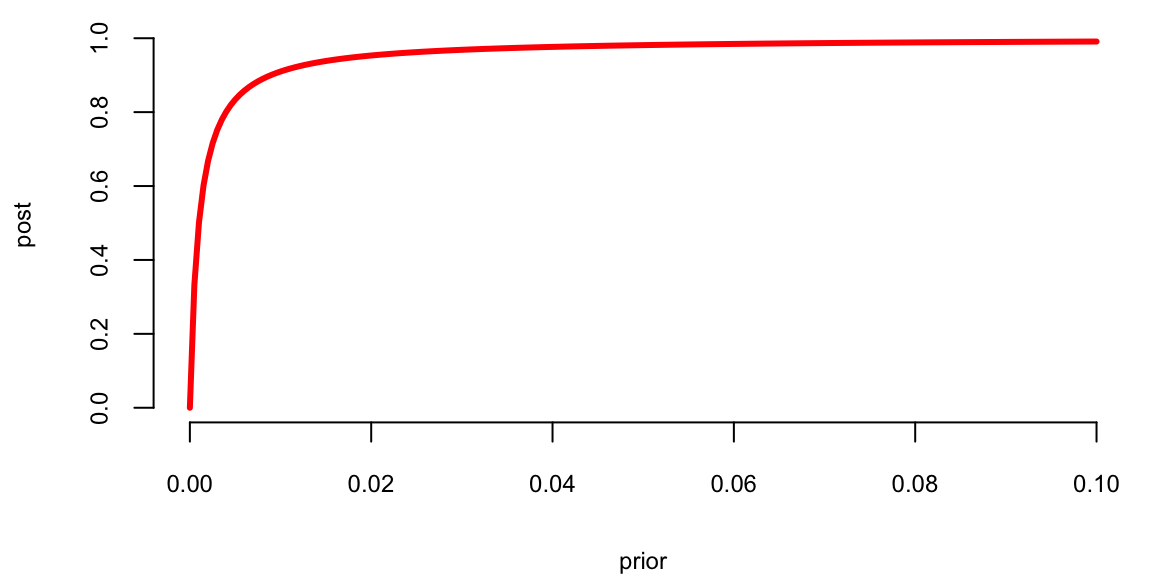
Now, suppose that you hear on the radio about a small earthquake while driving. Then, using Bayesian conditioning, \[ p(b=1 \mid a=1,r=1) = \dfrac{p(a,r \mid b)p(b)}{p(a,r)} \] and \[ p(a,r \mid b)p(b) = \dfrac{\sum_e p(b=1,e,a=1,r=1)}{\sum_b\sum_ep(b,e,a=1,r=1)} \] \[ =\dfrac{\sum_ep(r=1 \mid e)p(a=1 \mid b=1,e)p(b=1)p(e)}{\sum_b\sum_ep(r=1 \mid e)p(a=1 \mid b,e)p(b)p(e)} \] which is \(\approx 2\%\) in our case. This effect is called explaining away, namely when new information explains some previously known fact.