data(iris)
y = iris$Petal.Length
# initialize theta
theta <- matrix(c(0, 0), nrow = 2, ncol = 1)
# learning rate
alpha <- 0.0001
# number of iterations
n_iter <- 1000
# gradient descent
for (i in 1:n_iter) {
# compute gradient
grad <- -2 * t(x) %*% (y - x %*% theta)
# update theta
theta <- theta - alpha * grad
}21 Gradient Descent
Traditional statistical models are estimated by maximizing likelihood and using the least squares algorithm for linear regression and weighted least squares or Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm for generalized linear models.
21.1 Deep Learning and Least Squares
The deep learning model approximates the relation between inputs \(x\) and outputs \(y\) using a non-linear function \(f(x,\theta)\), where \(\theta\) is a vector of parameters. The goal is to find the optimal value of \(\theta\) that minimizes the expected loss function, given a training data set \(D = \{x_i,y_i\}_{i=1}^n\). The loss function is a measure of discrepancy between the true value of \(y\) and the predicted value \(f(x,\theta)\). The loss function is usually defined as the negative log-likelihood function of the model. \[ l(\theta) = - \sum_{i=1}^n \log p(y_i | x_i, \theta), \] where \(p(y_i | x_i, \theta)\) is the conditional distribution of \(y_i\) given \(x_i\) and \(\theta\). Thus, in the case of regression, we have \[ y_i = f(x_i,\theta) + \epsilon, ~ \epsilon \sim N(0,\sigma^2), \] Thus, the loss function is \[ l(\theta) = - \sum_{i=1}^n \log p(y_i | x_i, \theta) = \sum_{i=1}^n (y_i - f(x_i, \theta))^2, \]
21.2 Regression
Regression is simply a neural network which is wide and shallow. The insight of DL is that you use a deep and shallow neural network. Let’s look at a simple example and fit a linear regression model to iris dataset.
data(iris)
y = iris$Petal.Length
loss = function(theta) sum((y - x %*% theta)^2)
grad = function(theta) -2 * t(x) %*% (y - x %*% theta)
res = optim(c(0,0), loss, grad, method="BFGS")
theta = res$parOur loss minimization algorithm finds the following coefficients
| Intercept (\(\theta_1\)) | Petal.Width (\(\theta_2\)) |
|---|---|
| 1.1 | 2.2 |
Let’s plot the data and model estimated using gradient descent
plot(x[,2],y,pch=16, xlab="Petal.Width")
abline(theta[2],theta[1], lwd=3,col="red")
Let’s compare it to the standard estimation algorithm
m = lm(Petal.Length~Petal.Width, data=iris)| (Intercept) | Petal.Width |
|---|---|
| 1.1 | 2.2 |
The values found by gradient descent are very close to the ones found by the standard OLS algorithm.
21.3 Logistic Regression
Logistic regression is a generalized linear model (GLM) with a logit link function, defined as: \[ \log \left(\frac{p}{1-p}\right) = \theta_0 + \theta_1 x_1 + \ldots + \theta_p x_p, \] where \(p\) is the probability of the positive class. The negative log-likelihood function for logistic regression is a cross-entropy loss \[ l(\theta) = - \sum_{i=1}^n \left[ y_i \log p_i + (1-y_i) \log (1-p_i) \right], \] where \(p_i = 1/\left(1 + \exp(-\theta_0 - \theta_1 x_{i1} - \ldots - \theta_p x_{ip})\right)\). The derivative of the negative log-likelihood function is \[ \nabla l(\theta) = - \sum_{i=1}^n \left[ y_i - p_i \right] \begin{pmatrix} 1 \\ x_{i1} \\ \vdots \\ x_{ip} \end{pmatrix}. \] In matrix notations, we have \[ \nabla l(\theta) = - X^T (y - p). \] Let’s implement gradient descent algorithm now.
y = ifelse(iris$Species=="setosa",1,0)
x = cbind(rep(1,150),iris$Sepal.Length)
lrgd = function(x,y, alpha, n_iter) {
theta <- matrix(c(0, 0), nrow = 2, ncol = 1)
for (i in 1:n_iter) {
# compute gradient
p = 1/(1+exp(-x %*% theta))
grad <- -t(x) %*% (y - p)
# update theta
theta <- theta - alpha * grad
}
return(theta)
}
theta = lrgd(x,y,0.005,20000)The gradient descent parameters are
| Intercept (\(\theta_1\)) | Sepal.Length (\(\theta_2\)) |
|---|---|
| 28 | -5.2 |
And the plot is
par(mar=c(4,4,0,0), bty='n')
plot(x[,2],y,pch=16, xlab="Sepal.Length")
lines(x[,2],p,type='p', pch=16,col="red")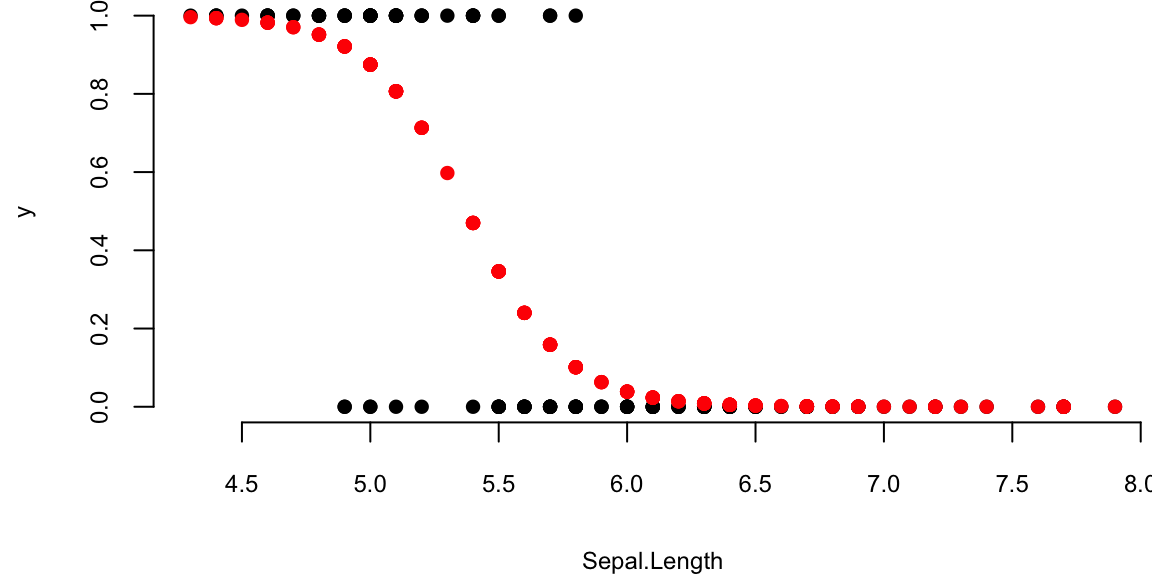
Let’s compare it to the standard estimation algorithm
glm(y~x-1, family=binomial(link="logit"))
Call: glm(formula = y ~ x - 1, family = binomial(link = "logit"))
Coefficients:
x1 x2
27.83 -5.18
Degrees of Freedom: 150 Total (i.e. Null); 148 Residual
Null Deviance: 208
Residual Deviance: 72 AIC: 76Now, we demonstrate the gradient descent for estimating a generalized linear model (GLM), namely logistic regression. We will use the iris data set again and try to predict the species of the flower using the petal width as a predictor. We will use the following model \[
\log \left(\frac{p_i}{1-p_i}\right) = \theta_0 + \theta_1 x_i,
\] where \(p_i = P(y_i = 1)\) is the probability of the flower being of the species \(y_i = 1\) (setosa).
The negative log-likelihood function for logistic regression model is \[ l(\theta) = - \sum_{i=1}^n \left[ y_i \log p_i + (1-y_i) \log (1-p_i) \right], \] where \(p_i = 1/\left(1 + \exp(-\theta_0 - \theta_1 x_i)\right)\). The derivative of the negative log-likelihood function is \[ \nabla l(\theta) = - \sum_{i=1}^n \left[ y_i - p_i \right] \begin{pmatrix} 1 \\ x_i \end{pmatrix}. \] In matrix notations, we have \[ \nabla l(\theta) = - X^T (y - p). \]
21.4 Stochastic Gradient Descent
Stochastic gradient descent (SGD) is a variant of the gradient descent algorithm. The main difference is that instead of computing the gradient over the whole data set, SGD computes the gradient over a randomly selected subset of the data. This allows SGD to be applied to estimate models when data set is too large to fit into memory, which is often the case with the deep learning models. The SGD algorithm replaces the gradient of the negative log-likelihood function with the gradient of the negative log-likelihood function computed over a randomly selected subset of the data \[ \nabla l(\theta) \approx \dfrac{1}{|B|} \sum_{i \in B} \nabla l(y_i, f(x_i, \theta)), \] where \(B \in \{1,2,\ldots,n\}\) is the batch samples from the data set. This method can be interpreted as gradient descent using noisy gradients, which are typically called mini-batch gradients with batch size \(|B|\).
The SGD is based on the idea of stochastic approximation introduced by Robbins and Monro (1951). Stochastic simply replaces \(F(l)\) with its Monte Carlo approximation.
In a small mini-batch regime, when \(|B| \ll n\) and typically \(|B| \in \{32,64,\ldots,1024\}\) it was shown that SGD converges faster than the standard gradient descent algorithm, it does converge to minimizers of strongly convex functions (negative log-likelihood function from exponential family is strongly convex) (Bottou, Curtis, and Nocedal 2018) and it is more robust to noise in the data (Hardt, Recht, and Singer 2016). Further, it was shown that it can avoid saddle-points, which is often an issue with deep learning log-likelihood functions. In the case of multiple-minima, SGD can find a good solution LeCun et al. (2002), meaning that the out-of-sample performance is often worse when trained with large- batch methods as compared to small-batch methods.
Now, we implement SGD for logistic regression and compare performance for different batch sizes
lrgd_minibatch = function(x,y, alpha, n_iter, bs) {
theta <- matrix(c(0, 0), nrow = 2, ncol = n_iter+1)
n = length(y)
for (i in 1:n_iter) {
s = ((i-1)*bs+1)%%n
e = min(s+bs-1,n)
xl = x[s:e,]; yl = y[s:e]
p = 1/(1+exp(-xl %*% theta[,i]))
grad <- -t(xl) %*% (yl - p)
# update theta
theta[,i+1] <- theta[,i] - alpha * grad
}
return(theta)
}Now run our SGD algorithm with different batch sizes.
set.seed(92) # kuzy
ind = sample(150)
y = ifelse(iris$Species=="setosa",1,0)[ind] # shuffle data
x = cbind(rep(1,150),iris$Sepal.Length)[ind,] # shuffle data
nit=200000
lr = 0.01
th1 = lrgd_minibatch(x,y,lr,nit,5)
th2 = lrgd_minibatch(x,y,lr,nit,15)
th3 = lrgd_minibatch(x,y,lr,nit,30)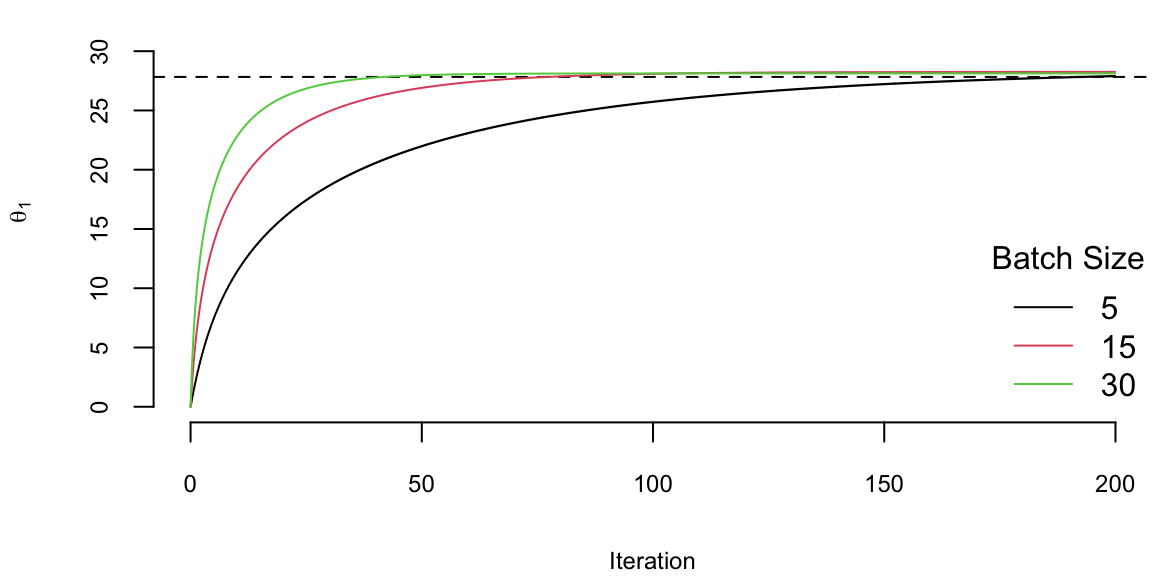
We run it with 2^{5} iterations and the learning rate of 0.01 and plot the values of \(\theta_1\) every 1000 iteration. There are a couple of important points we need to highlight when using SGD. First, we shuffle the data before using it. The reason is that if the data is sorted in any way (e.g. by date or by value of one of the inputs), then data within batches can be highly correlated, which reduces the convergence speed. Shuffling helps avoiding this issue. Second, the larger the batch size, the smaller number of iterations are required for convergence, which is something we would expect. However, in this specific example, from the number of computation point of view, the batch size does not change the number calculations required overall. Let’s look at the same plot, but scale the x-axis according to the amount of computations
plot(ind/1000,th1[1,ind], type='l', ylim=c(0,33), col=1, ylab=expression(theta[1]), xlab="Iteration")
abline(h=27.83, lty=2)
lines(ind/1000*3,th2[1,ind], type='l', col=2)
lines(ind/1000*6,th3[1,ind], type='l', col=3)
legend("bottomright", legend=c(5,15,30),col=1:3, lty=1, bty='n',title = "Batch Size")
There are several important considerations about choosing the batch size for SGD.
- The larger the batch size, the more memory is required to store the data.
- Parallelization is more efficient with larger batch sizes. Modern harware supports parallelization of matrix operations, which is the main operation in SGD. The larger the batch size, the more efficient the parallelization is. Usually there is a sweet spot \(|B|\) for the batch size, which is the largest batch size that can fit into the memory or parallelized. Meaning it takes the same amount of time to compute SGD step for batch size \(1\) and \(B\).
- Third, the larger the batch size, the less noise in the gradient. This means that the larger the batch size, the more accurate the gradient is. However, it was empirically shown that in many applications we should prefer noisier gradients (small batches) to obtain high quality solutions when the objective function (negative log-likelihood) is non-convex (Keskar et al. 2016).
Deep learning estimation problem as well as a large number of statistical problems, can be expressed in the form \[ \min l(x) + \phi(x). \] In learning \(l(x)\) is the negative log-likelihood and \(\phi(x)\) is a penalty function that regularizes the estimate. From the Bayesian perspective, the solution to this problem may be interpreted as a maximum a posteriori \[p(y\mid x) \propto \exp\{-l(x)\}, ~ p(x) \propto \exp\{-\phi(x)\}.\]
Second order optimisation algorithms, such as BFGS used for traditional statistical models do not work well for deep learning models. The reason is that the number of parameters a DL model has is large and estimating second order derivatives (Hessian or Fisher information matrix) becomes prohibitive from both computational and memory use standpoints. Instead, first order gradient descent methods are used for estimating parameters of a deep learning models.
The problem of parameter estimation (when likelihood belongs to the exponential family) is an optimisation problem
\[ \min_{\theta} l(\theta) := \dfrac{1}{n} \sum_{i=1}^n \log p(y_i, f(x_i, \theta)) \] where \(l\) is the negative log-likelihood of a sample, and \(\theta\) is the vector of parameters. The gradient descent method is an iterative algorithm that starts with an initial guess \(\theta^{0}\) and then updates the parameter vector \(\theta\) at each iteration \(t\) as follows: \[ \theta^{t+1} = \theta^t - \alpha_t \nabla l(\theta^t). \]
Let’s demonstrate these algorithms on a simple example of linear regression. We will use the mtcars data set and try to predict the fuel consumption (mpg) \(y\) using the number of cylinders (cyl) as a predictor \(x\). We will use the following model: \[
y_i = \theta_0 + \theta_1 x_i + \epsilon_i,
\] or in matrix form \[
y = X \theta + \epsilon,
\] where \(\epsilon_i \sim N(0, \sigma^2)\), \(X = [1 ~ x]\) is the design matrix with first column beign all ones.
The negative log-likelihood function for the linear regression model is \[ l(\theta) = \sum_{i=1}^n (y_i - \theta_0 - \theta_1 x_i)^2. \]
The gradient then is \[ \nabla l(\theta) = -2 \sum_{i=1}^n (y_i - \theta_0 - \theta_1 x_i) \begin{pmatrix} 1 \\ x_i \end{pmatrix}. \] In matrix form, we have \[ \nabla l(\theta) = -2 X^T (y - X \theta). \]
21.5 Automatic Differentiation (Backpropagation)
To calculate the value of the gradient vector, at each step of the optimization process, deep learning libraries require calculations of derivatives. In general, there are three different ways to calculate those derivatives. First, is numerical differentiation, when a gradient is approximated by a finite difference \(f'(x) = (f(x+h)-f(x))/h\) and requires two function evaluations. However, the numerical differentiation is not backward stable (Griewank, Kulshreshtha, and Walther 2012), meaning that for a small perturbation in input value \(x\), the calculated derivative is not the correct one. Second, is a symbolic differentiation which has been used in symbolic computational frameworks such as Mathematica or Maple for decades. Symbolic differentiation uses a tree form representation of a function and applies chain rule to the tree to calculate the symbolic derivative of a given function. Figure @ref(fig:comp-graph) shows a tree representation of of composition of affine and sigmoid functions (the first layer of our neural network).

The advantage of symbolic calculations is that the analytical representation of derivative is available for further analysis. For example, when derivative calculation is in an intermediate step of the analysis. Third way to calculate a derivative is to use automatic differentiation (AD). Similar to symbolic differentiation, AD recursively applies the chain rule and calculates the exact value of derivative and thus avoids the problem of numerical instability. The difference between AD and symbolic differentiation is that AD provides the value of derivative evaluated at a specific point, rather than an analytical representation of the derivative.
AD does not require analytical specification and can be applied to a function defined by a sequence of algebraic manipulations, logical and transient functions applied to input variables and specified in a computer code. AD can differentiate complex functions which involve IF statements and loops, and AD can be implemented using either forward or backward mode. Consider an example of calculating a derivative of the following function with respect to x.
sigmoid = function(x,b,w){
v1 = w*x;
v2 = v1 + b
v3 = 1/(1+exp(-v2))
}In the forward mode an auxiliary variable, called a dual number, will be added to each line of the code to track the value of the derivative associated with this line. In our example, if we set x=2, w=3, b=52, we get the calculations given in Table below.
| Function calculations | Derivative calculations |
|---|---|
1. v1 = w*x = 6 |
1. dv1 = w = 3 (derivative of v1 with respect to x) |
2. v2 = v1 + b = 11 |
2. dv2 = dv1 = 3 (derivative of v2 with respect to x) |
3. v3 = 1/(1+exp(-v2)) = 0.99 |
3. dv3 = eps2*exp(-v2)/(1+exp(-v2))**2 = 5e-05 |
Variables dv1,dv2,dv3 correspond to partial (local) derivatives of each intermediate variables v1,v2,v3 with respect to \(x\), and are called dual variables. Tracking for dual variables can either be implemented using source code modification tools that add new code for calculating the dual numbers or via operator overloading.
The reverse AD also applies chain rule recursively but starts from the outer function, as shown in Table below.
| Function calculations | Derivative calculations |
|---|---|
1. v1 = w*x = 6 |
4. dv1dx =w; dv1 = dv2*dv1dx = 3*1.3e-05=5e-05 |
2. v2 = v1 + b = 11 |
3. dv2dv1 =1; dv2 = dv3*dv2dv1 = 1.3e-05 |
3. v3 = 1/(1+exp(-v2)) = 0.99 |
2. dv3dv2 = exp(-v2)/(1+exp(-v2))**2; |
4. v4 = v3 |
1. dv4=1 |
For DL, derivatives are calculated by applying reverse AD algorithm to a model which is defined as a superposition of functions. A model is defined either using a general purpose language as it is done in PyTorch or through a sequence of function calls defined by framework libraries (e.g. in TensorFlow). Forward AD algorithms calculate the derivative with respect to a single input variable, but reverse AD produces derivatives with respect to all intermediate variables. For models with many parameters, it is much more computationally feasible to perform the reverse AD.
In the context of neural networks, the reverse AD algorithms is called back-propagation and was popularized in AI by Rumelhart, Hinton, and Williams (1986). According to Schmidhuber (2015) the first version of what we call today back-propagation was published in 1970 in a master’s thesis Linnainmaa (1970) and was closely related to the work of Ostrovskii, Volin, and Borisov (1971). However, similar techniques rooted in Pontryagin’s maximization principle Boltyanskii, Gamkrelidze, and Pontryagin (1960) were discussed in the context of multi-stage control problems Bryson (1961),bryson1969applied}. Dreyfus (1962) applies back-propagation to calculate the first order derivative of a return function to numerically solve a variational problem. Later Dreyfus (1973) used back-propagation to derive an efficient algorithm to solve a minimization problem. The first neural network specific version of back-propagation was proposed in P. Werbos (1974) and an efficient back-propagation algorithm was discussed in P. J. Werbos (1982).
Modern deep learning frameworks fully automate the process of finding derivatives using AD algorithms. For example, PyTorch relies on autograd library which automatically finds gradient using back-propagation algorithm. Here is a small code example using autograd library in jax.
import jax.numpy as jnp
from jax import grad,jit
import pandas as pd
from jax import random
import matplotlib.pyplot as plt
def abline(slope, intercept):
"""Plot a line from slope and intercept"""
axes = plt.gca()
x_vals = jnp.array(axes.get_xlim())
ylim = axes.get_xlim()
y_vals = intercept + slope * x_vals
plt.plot(x_vals, y_vals, '-'); plt.ylim(ylim)
d = pd.read_csv('../data/circle.csv').values
x = d[:, 1:3]; y = d[:, 0]
def sigmoid(x):
return 1 / (1 + jnp.exp(-x))
def predict(x, w1,b1,w2,b2):
z = sigmoid(jnp.dot(x, w1)+b1)
return sigmoid(jnp.dot(z, w2)+b2)[:,0]
def nll(x, y, w1,b1,w2,b2):
yhat = predict(x, w1,b1,w2,b2)
return -jnp.sum(y * jnp.log(yhat) + (1 - y) * jnp.log(1 - yhat))
@jit
def sgd_step(x, y, w1,b1,w2,b2, lr):
grads = grad(nll,argnums=[2,3,4,5])(x, y, w1,b1,w2,b2)
return w1 - lr * grads[0],b1 - lr * grads[1],w2 - lr * grads[2],b2 - lr * grads[3]
def accuracy(x, y, w1,b1,w2,b2):
y_pred = predict(x, w1,b1,w2,b2)
return jnp.mean((y_pred > 0.5) == y)
k = random.PRNGKey(0)
w1 = 0.1*random.normal(k,(2,4))
b1 = 0.01*random.normal(k,(4,))
w2 = 0.1*random.normal(k,(4,1))
b2 = 0.01*random.normal(k,(1,))
for i in range(1000):
w1,b1,w2,b2 = sgd_step(x,y,w1,b1,w2,b2,0.003)
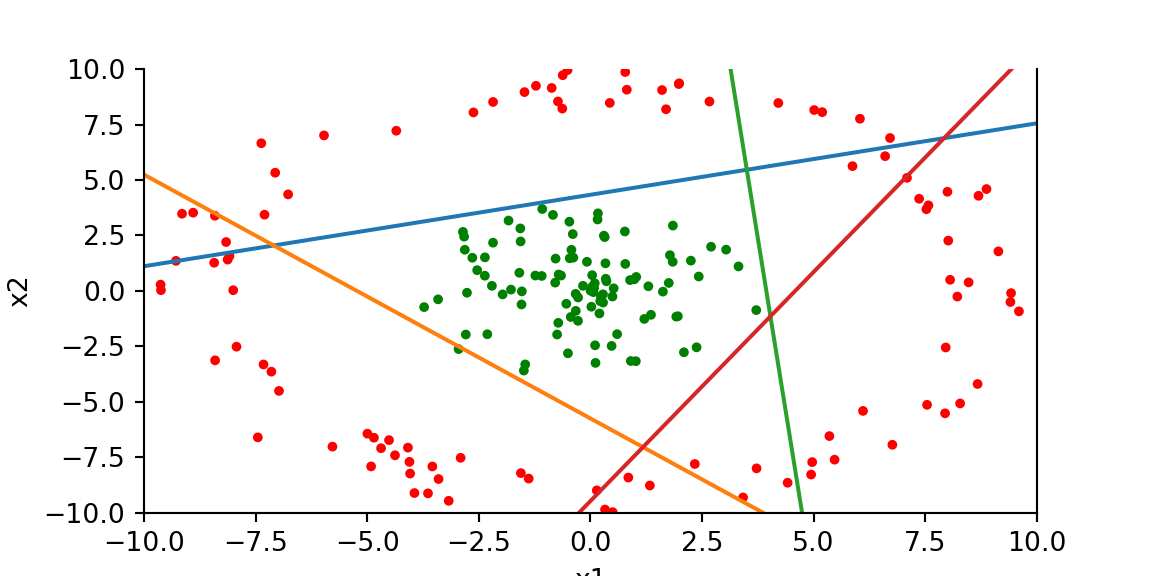
print(accuracy(x,y,w1,b1,w2,b2))1.0fig, ax = plt.subplots()
ax.scatter(x[:,0], x[:,1], c=['r' if x==1 else 'g' for x in y],s=7); plt.xlabel("x1"); plt.ylabel("x2"); plt.xlim(-10,10)<matplotlib.collections.PathCollection object at 0x17f003b00>
Text(0.5, 0, 'x1')
Text(0, 0.5, 'x2')
(-10.0, 10.0)ax.spines['top'].set_visible(False)
# plt.scatter((x[:,1]*w1[1,0] - b1[0])/w1[0,0], x[:,1])
abline(w1[1,0]/w1[0,0],b1[0]/w1[0,0])
abline(w1[1,1]/w1[0,1],b1[1]/w1[0,1])
abline(w1[1,2]/w1[0,2],b1[2]/w1[0,2])
abline(w1[1,3]/w1[0,3],b1[3]/w1[0,3])
plt.show()