This chapter explores the theoretical foundations of deep learning through the lens of multivariate function approximation. We begin with ridge functions as fundamental building blocks—functions of the form \(f(x) = g(w^Tx)\) that represent one of the simplest forms of nonlinear multivariate functions by combining a single linear projection with a univariate nonlinear transformation. Their key geometric property—remaining constant along directions orthogonal to the projection vector \(w\)—makes them particularly useful for high-dimensional approximation.
Building on ridge functions, we introduce projection pursuit regression, which approximates complex input-output relationships using linear combinations of ridge functions. This technique, developed in the 1980s, provides the mathematical foundation for understanding how neural networks decompose high-dimensional problems.
The chapter culminates with the Kolmogorov Superposition Theorem (KST), a profound result showing that any real-valued continuous function can be represented as a sum of compositions of single-variable functions. This theorem provides a theoretical framework for understanding how multivariate functions can be decomposed into simpler, more manageable components—a principle that underlies the architecture of modern neural networks.
Throughout, we examine a central question: can we achieve superior performance through mathematically elegant representations of multivariate functions rather than raw computational power? This tension between theoretical efficiency and practical computation motivates much of the research in deep learning theory.
20.1 Ridge and Projection Pursuit Regression
To understand the significance of this trade-off, we consider ridge functions, which represent a fundamental building block in multivariate analysis. Since our ultimate goal is to model arbitrary multivariate functions \(f\), we need a way to reduce dimensionality while preserving the ability to capture nonlinear relationships. Ridge functions accomplish this by representing one of the simplest forms of nonlinear multivariate functions, requiring only a single linear projection and a univariate nonlinear transformation. Formally, a ridge function \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) takes the form \(f(x) = g(w^Tx)\), where \(g\) is a univariate function and \(x,w \in \mathbb{R}^n\). The non-zero vector \(w\) is called the direction. The term “ridge” reflects a key geometric property: the function remains constant along any direction orthogonal to \(w\). Specifically, for any direction \(u\) such that \(w^Tu = 0\), we have
\[
f(x+u) = g(w^T(x+u)) = g(w^Tx) = f(x)
\]
This structural simplicity makes ridge functions particularly useful as building blocks for high-dimensional approximation.
Ridge functions play a central role in high-dimensional statistical analysis. For example, projection pursuit regression approximates input-output relations using a linear combination of ridge functions (Friedman and Stuetzle 1981; Huber 1985): \[
\phi(x) = \sum_{i=1}^{p}g_i(w_i^Tx),
\] where both the directions \(w_i\) and functions \(g_i\) are learnable parameters, and \(w_i^Tx\) represents the one-dimensional projection of the input vector \(x\) onto the direction defined by \(w_i\). Each \(g_i(w_i^Tx)\) can be interpreted as a learned feature extracted from the data. Diaconis and Shahshahani (1984) extended this approach using nonlinear functions of linear combinations, establishing the mathematical framework that would later inform the design of multi-layer neural networks.
From Approximation to Representation
While ridge functions and projection pursuit provide powerful approximation tools, they rely on sums of increasing numbers of components to achieve precision. A fundamental question in deep learning theory is whether we can achieve exact representation of multivariate functions using a finite number of components, rather than just approximation.
This question addresses a core tension in machine learning: the trade-off between the mathematical efficiency of a representation and its computational feasibility. Modern deep learning succeeds not just because of hardware acceleration (GPUs), but because deep architectures may implicitly leverage efficient representations of high-dimensional functions.
To understand this, we turn to a foundational result that seemingly solves the representation problem entirely: the Kolmogorov Superposition Theorem.
20.2 Kolmogorov Superposition Theorem (KST)
Kolmogorov demonstrated that any real-valued continuous function \(f(\mathbf{x})\) on \(E^n\) can be represented as a composition of single-variable functions:
where \(g_q\) are continuous single-variable functions defined on \(\phi_q(E^n)\). Kolmogorov further showed that the \(\phi_q\) functions can be decomposed into sums of single-variable functions:
The theorem has been refined over time, with inner functions becoming Hölder continuous and Lipschitz continuous, requiring modifications to both outer and inner functions.
The inner functions \(\psi_{q,i}\) partition the input space into distinct regions, and the outer function \(g\) must be constructed to provide the correct output values across these regions. For each input configuration, the inner functions generate a unique encoding, and \(g\) must map this encoding to the appropriate value of \(f(x)\). This creates a dictionary-like structure that associates each region with its corresponding output value.
The constructive proof of KST has been refined through several contributions. Sprecher (1965) provided the first explicit construction of the inner functions, though his proof contained technical gaps. Köppen (2000) corrected these errors and provided a complete algorithmic construction. More recently, Actor (2018) and Dembo (2021) proposed computational improvements to the algorithm. Braun and Riedmiller (2009) further enhanced the understanding by providing precise definitions of the shift parameters \(\delta_k\) and characterizing the topological structure induced by the inner functions.
A fundamental trade-off in KST exists between function smoothness and dimensionality. The inner functions \(\psi_{p,q}\) can be chosen from two different function spaces, each offering distinct advantages. The first option is to use functions from \(C^1([0,1])\)—the space of continuously differentiable functions—but this limits the network’s ability to handle higher dimensions effectively. The second option is to relax the smoothness requirement to Hölder continuous functions (\(\psi_{p,q} \in \text{Hölder}_\alpha([0,1])\)), which satisfy the inequality \(\|\psi(\mathbf{x}) - \psi(\mathbf{y})\| < \|\mathbf{x}-\mathbf{y}\|^\alpha\) for vector-valued inputs. These functions are less smooth, but this “roughness” enables better approximation in higher dimensions.
Kolmogorov-Arnold Networks
A significant development has been the emergence of Kolmogorov-Arnold Networks (KANs). The key innovation of KANs is their use of learnable functions rather than weights on the network edges. This replaces traditional linear weights with univariate functions, typically parametrized by splines, enhancing both representational capacity and interpretability.
There is a practical connection between KST and neural networks by showing that any KAN can be constructed as a 3-layer MLP. Consider a KST in the form of sums of functions, a two layer model:
This structure enables fast, scalable algorithms that avoid backpropagation for any GAM model through projection descent with Kaczmarz schemes—iterative methods originally developed for solving systems of linear equations that can be adapted for training these networks (Kaczmarz 1937).
Rather than using learnable functions as network node activations, Polson and Sokolov directly use KST representation. This 2-layer network with non-differentiable inner function has architecture:
The most striking aspect of KST is that it leads to a Generalized Additive Model (GAM) with fixed features that are independent of the target function \(f\). These features, determined by the Koppen function, provide universal topological information about the input space, effectively implementing a k-nearest neighbors structure that is inherent to the representation.
This leads to the following architecture. Any deep learner can be represented as a GAM with feature engineering (topological information) given by features \(z_k\) in the hidden layer:
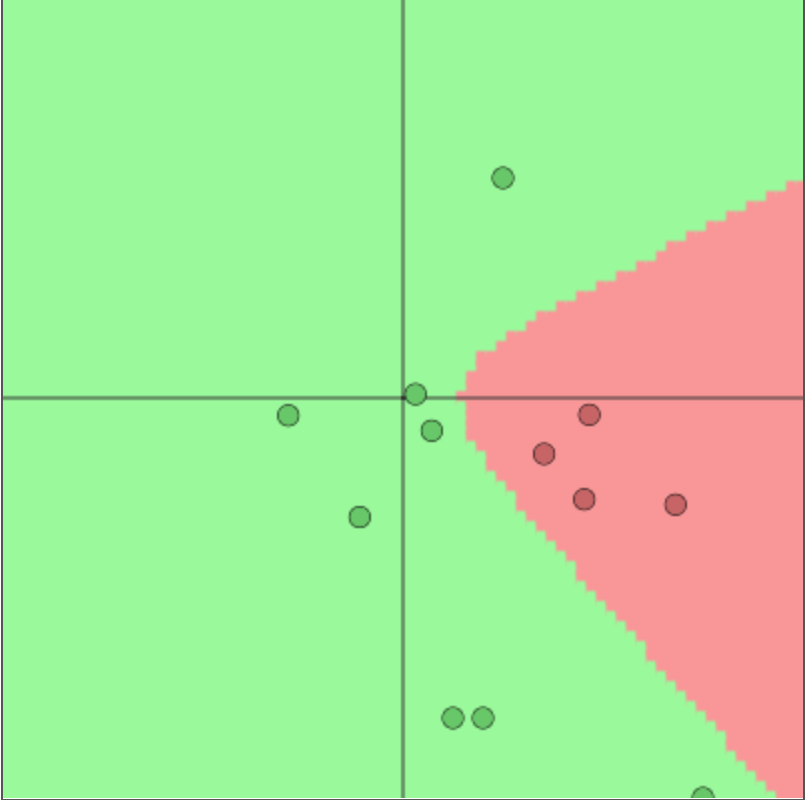
The partitioning of the input space by a deep learner is similar to that performed by decision trees and partition-based models such as CART, MARS, and RandomForests. However, trees are more local in the regions that they use to construct their estimators. Each neuron in a deep learning model corresponds to a manifold that divides the input space. In the case of the ReLU activation function \(f(x) = \max(0,x)\), the manifold is simply a hyperplane. The neuron activates when the new observation is on the “right” side of this hyperplane, with the activation magnitude equal to the distance from the boundary. For example, in two dimensions, three neurons with ReLU activation functions will divide the space into seven regions, as shown in Figure 20.1.
Figure 20.1: Space partition by three ReLU neurons in 2D.
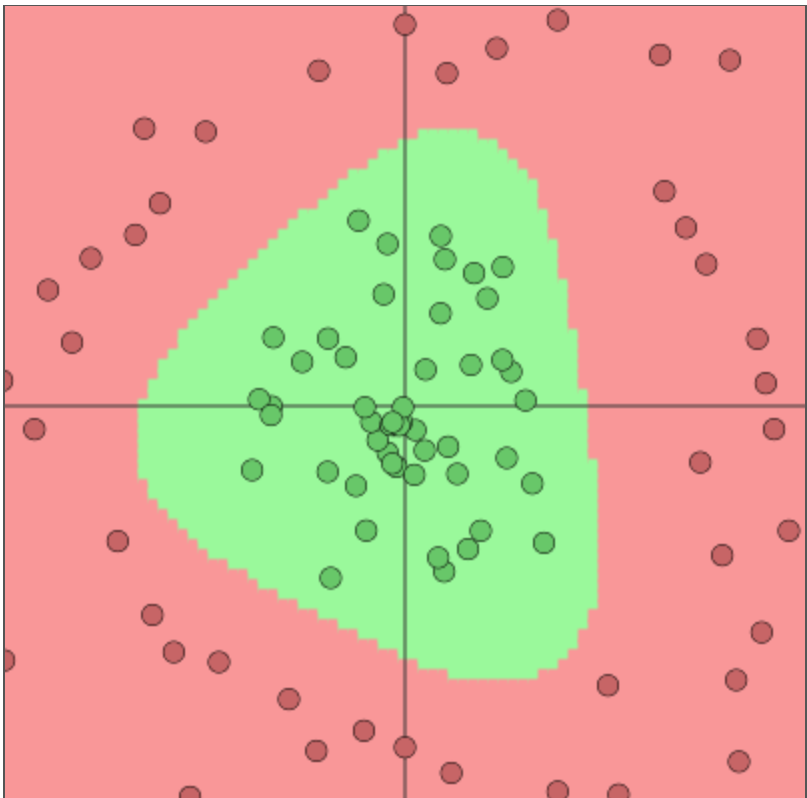
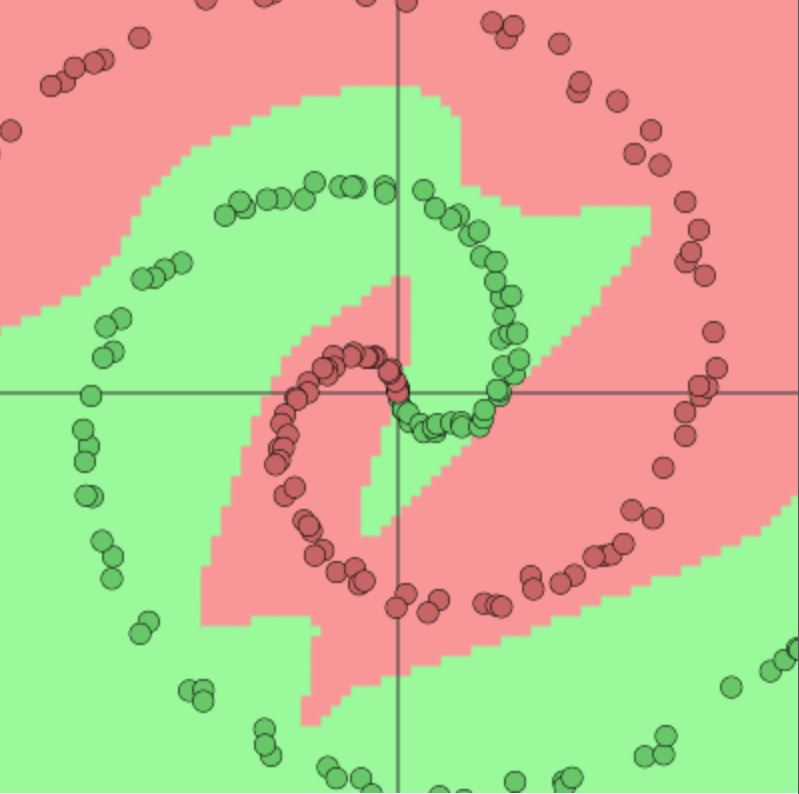
The key difference between tree-based architectures and neural network-based models lies in how hyperplanes are combined. Figure 20.2 compares space decomposition by hyperplanes in tree-based versus neural network architectures. We compare a two-layer neural network (bottom row) with a tree model trained via the CART algorithm (top row). The network architecture used is:
The weight matrices for simple data are \(W^{(1)}, W^{(2)} \in \mathbb{R}^{2 \times 2}\); for circle data \(W^{(1)} \in \mathbb{R}^{2 \times 2}\) and \(W^{(2)} \in \mathbb{R}^{3 \times 2}\); and for spiral data we have \(W^{(1)} \in \mathbb{R}^{2 \times 2}\) and \(W^{(2)} \in \mathbb{R}^{4 \times 2}\). An advantage of deep architectures is that the number of hyperplanes grows exponentially with the number of layers.
Figure 20.2: Space partition by tree architectures (top row) and deep learning architectures (bottom row) for three different data sets.
Connection to Bayesian Model Averaging
This space partitioning perspective connects naturally to Bayesian ensemble methods. A Bayesian probabilistic approach can optimally weight predictors via model averaging:
\[
\hat{Y}(X) = \sum_{r=1}^R w_r \hat{Y}_r(X)
\]
where \(\hat{Y}_r(X) = \E{Y \mid X, \text{model } r}\) and weights \(w_r\) are posterior model probabilities. Amit, Blanchard, and Wilder (2000) demonstrated the success of multiple randomized classifiers (e.g., an ensemble of 100 trees), which reduces error rates significantly compared to single trees by exploiting the weak correlation between diverse classifiers.
20.5 Kernel Smoothing and Interpolation
The theory of kernel methods was developed by Fredholm in the context of integral equations (Fredholm 1903). The idea is to represent a function as a linear combination of basis functions, which are called kernels.
Here, the unknown function \(f(x)\) is represented as a linear combination of kernels \(K(x,x')\) with unknown coefficients \(\phi(x')\). The kernels are known, and the coefficients are unknown. The coefficients are found by solving the integral equation. The first work in this area was done by Abel who considered equations of the form above.
Nowadays, we call those equations Volterra integral equations of the first kind. Integral equations typically arise in inverse problems. Their significance extends beyond their historical origins, as kernel methods have become instrumental in addressing one of the fundamental challenges in modern mathematics: the curse of dimensionality.
Nadaraya (1964) and Watson (1964) independently proposed using kernels to estimate the regression function. The idea is to estimate \(f(x)\) at a point \(x\) by computing a weighted average of the response values \(y_i\) at nearby points \(x_i\), with the kernel function defining the weights.
Both Nadaraya and Watson considered the symmetric kernel \(K(x,x') = K(\|x'-x\|_2)\), where \(||\cdot||_2\) is the Euclidean norm. The most popular kernel of that sort is the Gaussian kernel:
Alternatively, replacing the 2-norm with inner products: \(K(x,x') = \exp(x^Tx'/2\sigma^2)\).
Kernel methods are supported by numerous generalization bounds which often take the form of inequalities that describe the performance limits of kernel-based estimators. A particularly important example is the Bayes risk for \(k\)-nearest neighbors (\(k\)-NN), which can be expressed in a kernel framework as:
\(k\)-NN classifiers converge to error rates bounded relative to Bayes error rate, with relationships depending on class number. For binary classification, asymptotic \(k\)-NN error rate is at most \(2R^*(1-R^*)\) where \(R^*\) is Bayes error rate. Cover and Hart proved interpolated \(k\)-NN schemes are consistent estimators with performance improving as sample size increases.
20.6 Transformers as Kernel Smoothing
Bahdanau, Cho, and Bengio (2014) proposed kernel smoothing for sequence-to-sequence learning, estimating next-word probability using context vectors—weighted averages of input sequence vectors \(h_j\):
\[
c_i = \sum_{j=1}^n \alpha_{ij} h_j,
\]
where weights \(\alpha_{ij}\) are defined by the kernel function:
Instead of using a traditional similarity measure like the 2-norm or inner product, the authors used a neural network to define the energy function \(e_{ij} = a(s_{i-1},h_j)\). This neural network measures the similarity between the last generated element of the output sequence \(s_{i-1}\) and \(j\)-th element of the input sequence \(h_j\). The resulting context vector is then used to predict the next word in the sequence.
Transformer
Transformers have become the dominant architecture for natural language processing, achieving state-of-the-art results across tasks from machine translation to language modeling and text generation. Originally designed to handle sequential data, the transformer architecture has since been extended to computer vision (Vision Transformers), protein structure prediction (AlphaFold), and speech recognition. Its success stems from a novel self-attention mechanism that efficiently captures long-range dependencies.
The idea to use kernel smoothing for sequence to sequence was called “attention”, or cross-attention, by Bahdanau, Cho, and Bengio (2014). When used for self-supervised learning, it is called self-attention. When a sequence is mapped to a matrix \(M\), it is called multi-head attention. The concept of self-attention and attention for natural language processing was further developed by Vaswani et al. (2023) who developed a smoothing method that they called the transformer.
The transformer architecture revolves around a series of mathematical concepts and operations:
Embeddings: The input text is converted into vectors using embeddings. Each word (or token) is represented by a unique vector in a high-dimensional space.
Positional Encoding: Since transformers do not have a sense of sequence order (like RNNs do), positional encodings are added to the embeddings to provide information about the position of each word in the sequence.
Multi-Head Attention: The core of the transformer model. It enables the model to focus on different parts of the input sequence simultaneously. The attention mechanism is defined as: \[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \] where \(Q\), \(K\), and \(V\) are query, key, and value matrices respectively.
Query (Q), Key (K), and Value (V) Vectors: These are derived from the input embeddings. They represent different aspects of the input.
Scaled Dot-Product Attention: The attention mechanism calculates the dot product of the Query with all Keys, scales these values, and then applies a softmax function to determine the weights of the Values.
Multiple ‘Heads’: The model does this in parallel multiple times (multi-head), allowing it to capture different features from different representation subspaces.
Layer Normalization and Residual Connections: After each sub-layer in the encoder and decoder (like multi-head attention or the feed-forward layers), the transformer applies layer normalization and adds the output of the sub-layer to its input (residual connection). This helps in stabilizing the training of deep networks.
Feed-Forward Neural Networks: Each layer in the transformer contains a fully connected feed-forward network applied to each position separately and identically. It is defined as: \[ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 \] where \(W_1\), \(W_2\), \(b_1\), and \(b_2\) are learnable parameters.
Output Linear Layer and Softmax: The decoder’s final output passes through a linear layer followed by a softmax layer. This layer converts the decoder output into predicted next-token probabilities.
Training and Loss Function: Transformers are often trained using a variant of Cross-Entropy Loss to compare the predicted output with the actual output.
Masking: In the decoder, to prevent future tokens from being used in the prediction, a technique called ‘masking’ is applied.
Backpropagation and Optimization: The model’s parameters are adjusted through backpropagation and optimization algorithms like Adam.
Later, Lin et al. (2017) proposed using similar idea for self-supervised learning, where a sequence of words (sentence) is mapped to a single matrix:
\[
M = AH,
\]
where \(H\) is the matrix representing an input sequence \(H = (h_1,\ldots,h_n)\) and \(A\) is the matrix of weights:
\[
A = \mathrm{softmax}\left(W_2\tanh\left(W_1H^T\right)\right).
\]
This allows to represent a sequence of words of any length \(n\) using a “fixed size” \(r\times u\) matrix \(M\), where \(u\) is the dimension of a vector that represents an element of a sequence (word embedding) and \(r\) is the hyper-parameter that defines the size of the matrix \(M\).
The primary advantage of transformers over recurrent architectures is their parallelizability—all positions in a sequence can be processed simultaneously rather than sequentially. Modern large language models such as BERT (Devlin et al. 2019), GPT (Brown et al. 2020), and T5 (Raffel et al. 2020) are built on transformer architectures. The transformer’s ability to capture long-range dependencies through attention, combined with its scalability to massive datasets and model sizes, has made it the foundation for the current generation of AI systems. See Tsai et al. (2019) for a comprehensive survey of transformer applications beyond NLP.
20.7 Deep Learning as Representation Learning
A fundamental perspective on deep learning is that it automates the process of feature engineering. Formally, we seek to find a predictor \(\mathbf{Y} = f(\mathbf{X})\). We can decompose this function into two stages: a data transformation (representation learning) \(\phi(\mathbf{X})\) and a predictive model \(g(\cdot)\).
Here, \(\mathbf{Z}\) represents latent features. The transformation \(\phi(\cdot)\) effectively performs dimensionality reduction (or expansion) to uncover a structure where the relationship between \(\mathbf{Z}\) and \(\mathbf{Y}\) is simpler (often linear).
Dimensionality Expansion vs. Reduction
Classically, statisticians approached complex functions through dimensionality expansion (basis expansion). Methods like Kernel Regression or Splines map the input \(\mathbf{X}\) into a higher-dimensional space of features \(\phi(\mathbf{X}) = (\phi_1(\mathbf{X}), \ldots, \phi_M(\mathbf{X}))\) (e.g., interactions, polynomials) and then fit a linear model. The “Kernel Trick” allows this to be done efficiently without explicit computation of features.
Deep learning, in contrast, often emphasizes dimensionality reduction (feature learning). It searches for a low-dimensional manifold embedded in the high-dimensional input space.
Linear Baselines: PCA and PLS
To understand the contribution of deep learning, it is useful to compare it with linear methods for Representation Learning:
Principal Component Analysis (PCA): An unsupervised method that finds orthogonal directions (eigenvectors of \(\mathbf{X}^T\mathbf{X}\)) maximizing variance. It creates features \(\mathbf{Z}_{PCA} = \mathbf{X}\mathbf{W}\) without knowledge of the target \(\mathbf{Y}\).
Partial Least Squares (PLS): A supervised method that finds directions maximizing the covariance between \(\mathbf{X}\) and \(\mathbf{Y}\). It effectively finds features that are both variable and predictive.
Deep Neural Networks extrapolate this concept to the nonlinear regime. They can be viewed as performing Nonlinear PLS. The layers of a network apply successive semi-affine transformations:
This hierarchical stacking allows the network to learn progressively more abstract representations, discovering nonlinear factors that maximize predictive power, much like a nonlinear generalization of the supervised dimensionality reduction performed by PLS.
Uncertainty Quantification
We can extend this framework to quantify uncertainty. Our probabilistic model is \(\mathbf{Y} \mid \mathbf{Z} \sim p(\mathbf{Y} \mid \mathbf{Z})\), where \(\mathbf{Z} = g(\mathbf{X})\) is the deep feature extraction. A key result by Brillinger (2012) suggests that for certain input distributions (e.g., Gaussian), the central subspace estimated by methods like PLS or Deep Learning can be consistent.
By treating the top layer as a generalized linear model on learned features \(\mathbf{Z}\), we can leverage standard Bayesian techniques for the final prediction layer while relying on the deep network for feature discovery. This “Last Layer Bayesian” approach provides a practical path to uncertainty quantification in deep learning, enabling the calculation of predictive intervals: \[
\mathbf{Y}_{\star} \sim \int p(\mathbf{Y} \mid \mathbf{Z}_{\star}, \theta) p(\theta \mid \mathcal{D}) d\theta
\] where \(\theta\) represents the parameters of the output layer.
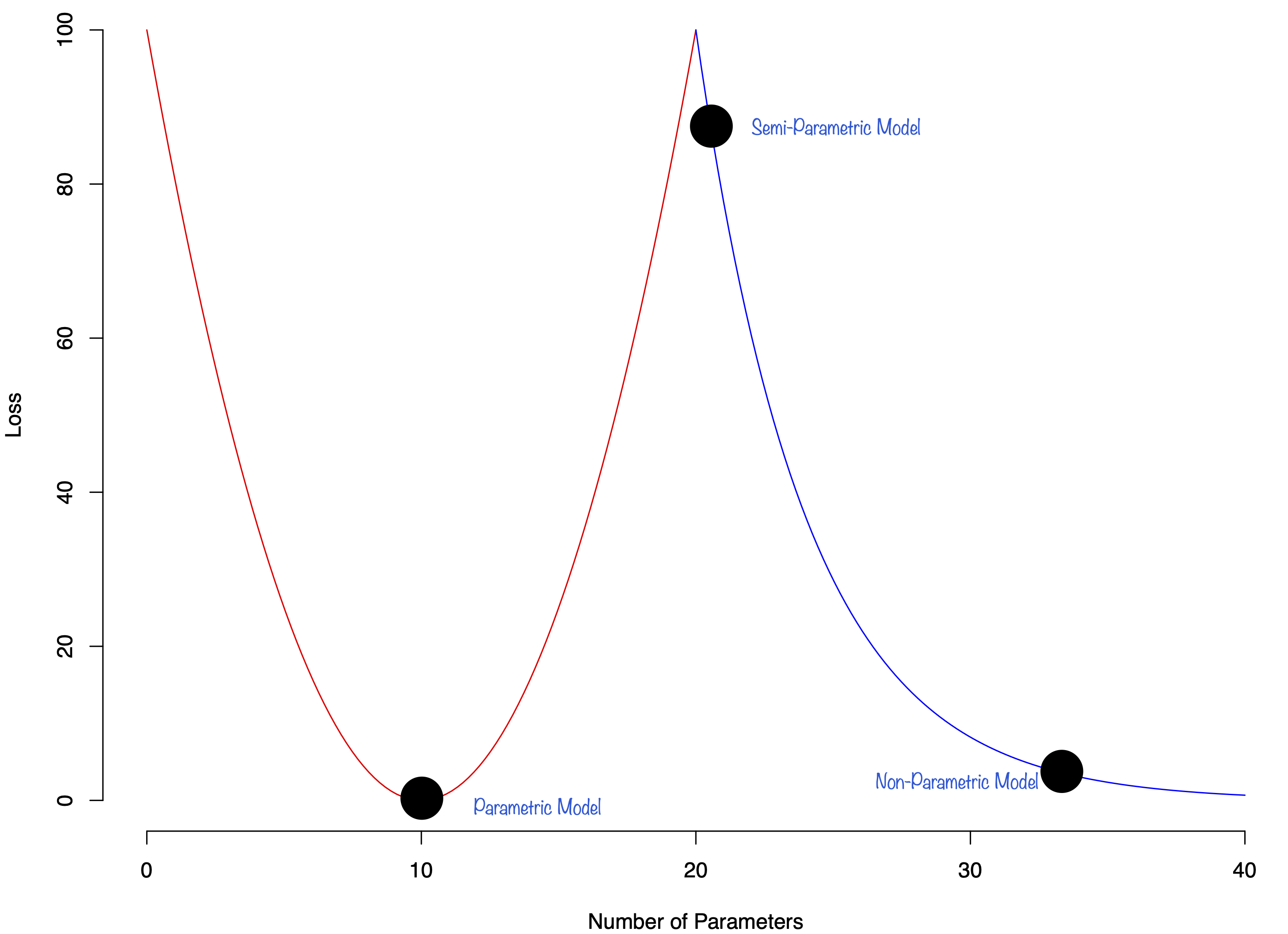
20.8 Double Descent
Double descent is a phenomenon of over-parameterized statistical models. In this section, we present a view of double descent from a Bayesian perspective. Over-parameterized models such as deep neural networks have an interesting re-descending property in their risk characteristics. This is a recent phenomenon in machine learning and has been the subject of many studies. As the complexity of the model increases, there is a U-shaped region corresponding to the traditional bias-variance trade-off, but then as the number of parameters equals the number of observations and the model becomes one of interpolation, the risk can become infinite and then, in the over-parameterized region, it re-descends—the double descent effect. We show that this has a natural Bayesian interpretation. Moreover, we show that it is not in conflict with the traditional Occam’s razor that Bayesian models possess, in that they tend to prefer simpler models when possible.
Empirically, the double descent effect was initially observed for high-dimensional neural network regression models and the good performance of these models on such tasks as large language models, image processing, and generative AI methods(Nareklishvili, Polson, and Sokolov 2023). The double descent effect extends the classical bias-variance trade-off curve that shrinkage estimators possess. This phenomenon was first observed in the context of linear regression(Belkin et al. 2019). The authors showed that the test error of the estimator can decrease as the number of parameters increases. Bach (2024) extends these results to stochastic regression models.
Interpolators—estimators that achieve zero training error—were then shown to have attractive properties due to the double descent effect(Hastie et al. 2022). Our goal is to show that Bayesian estimators can also possess a double descent phenomenon. Interpolators such as ReLU neural networks(Polson, Sokolov, et al. 2017) have increased in popularity with many applications such as traffic flow modeling(Polson, Sokolov, et al. 2017) and high-frequency trading(Dixon, Polson, and Sokolov 2019), among many others.
Occam’s razor—the favoring of simpler models over complex ones—is a natural feature of Bayesian methods that are based on the weight of evidence (a.k.a. the marginal likelihood of the data). To do this, they penalize models with higher complexity via a correction term as in the Bayesian Information Criterion (BIC). This seems inconsistent with the double descent phenomenon. We show that this is not the case, as even though Bayesian methods shift the posterior towards lower-complexity models, highly parameterized Bayesian models can also have good risk properties due to the conditional prior of parameters given the model. We illustrate this with an application to neural network models.
Double descent has been studied from a frequentist point of view in Belkin et al. (2019), Bach (2024). The phenomenon of double descent is illustrated in Figure 20.3. The first part of the curve represents the classical U-shaped bias-variance trade-off. The second part demonstrates the double descent phenomenon, where the test error of the estimator can decrease as the model becomes over-parameterized beyond the interpolation threshold. This phenomenon was later observed in the context of deep learning(Nakkiran et al. 2021). The authors showed that the test error of the estimator can decrease as the number of parameters increases.
Figure 20.3
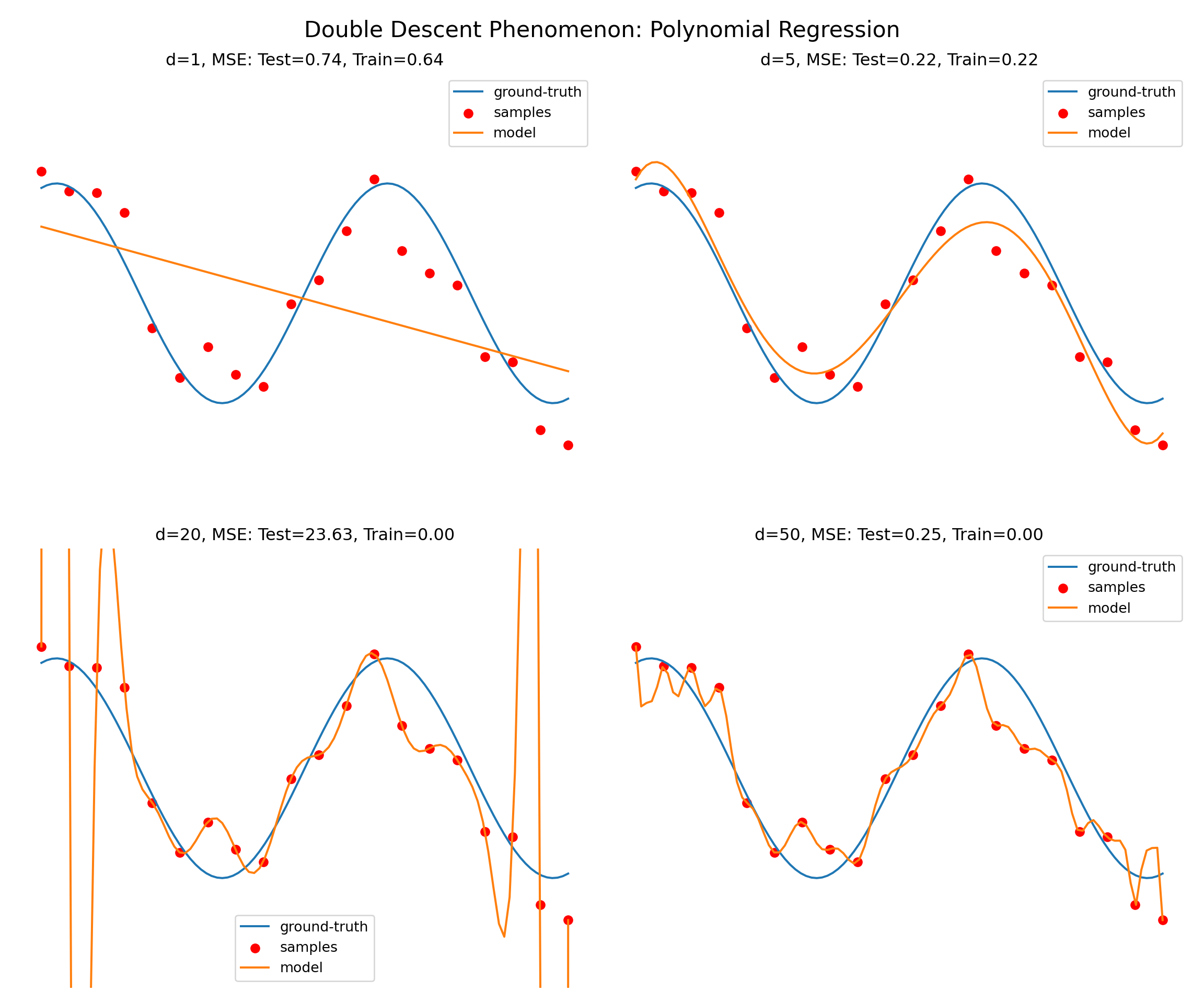
Example 20.1 (Double Descent Demonstration using Polynomial Regression) To illustrate the double descent phenomenon in a concrete setting, we present a detailed example using polynomial regression with Legendre basis functions. This example demonstrates how the test error can exhibit the characteristic U-shaped curve followed by a re-descent as model complexity increases far beyond the interpolation threshold.
Our demonstration uses a one-dimensional regression problem where we attempt to learn a sinusoidal function \(f(x) = \sin(5x)\) from a small dataset of only \(n = 20\) observations sampled from the interval \([-1, 1]\). We add Gaussian noise with standard deviation \(\sigma = 0.3\) to simulate realistic measurement error. The choice of a small sample size is crucial for observing double descent, as it creates a regime where the number of model parameters can substantially exceed the number of observations.
We fit polynomial models of varying degrees \(d = 1, 2, \ldots, 50\) using Legendre polynomial basis functions. Legendre polynomials provide a numerically stable orthogonal basis that helps avoid the numerical instabilities associated with standard monomial bases in high-degree polynomial fitting. For each degree \(d\), we estimate the coefficients using the Moore-Penrose pseudoinverse, which provides the minimum-norm solution when the system is overdetermined (i.e., when \(d > n\)).
Figure 20.4 illustrates how model behavior changes dramatically across different polynomial degrees. The four panels show representative cases that capture the key phases of the double descent phenomenon:
Degree 1 (Underparameterized): The linear model is too simple to capture the oscillatory nature of the underlying sine function, resulting in high bias and poor fit to both training and test data.
Degree 5 (Classical Optimum): This represents the sweet spot of the classical bias-variance tradeoff, where the model has sufficient complexity to capture the main features of the sine function without overfitting severely.
Degree 20 (Interpolation Threshold): At this degree, the model has exactly as many parameters as training observations, enabling perfect interpolation of the training data. However, the resulting fit exhibits wild oscillations between data points, leading to poor generalization performance.
Degree 50 (Over-parameterized): Surprisingly, despite having far more parameters than observations, this highly over-parameterized model achieves better test performance than the interpolating model, demonstrating the double descent effect.
Code
n =20# number of samplessigma =0.3# stdev of noisea =-1b =1# range of x values# Use Legendre polynomial basis by defaultG = np.polynomial.legendre.legvanderdef poly(pts, beta, d):return G(pts, d).dot(beta)# Initialize dataground_truth = sinx = np.linspace(a, b, n)y = ground_truth(x) + sigma * np.random.normal(size=n)xdense = np.linspace(a, b, 100)ygt = ground_truth(xdense)# Core functionsdef solve_reg(A, y, lamb):return la.solve(A.T.dot(A) + lamb * np.identity(A.shape[1]), A.T.dot(y))def fit(d): betaHat = la.pinv(G(x, d)).dot(y) mseos = np.sqrt(np.mean((G(xdense, d).dot(betaHat) - ygt)**2)) mseis = np.sqrt(np.mean((G(x, d).dot(betaHat) - y)**2))return betaHat, mseos, mseisdef run(d, ax):"""Compute the regressor for degree d, and plot the solution.""" betaHat, mseos, mseois = fit(d) ax.plot(xdense, ygt, label='ground-truth') ax.scatter(x, y, c='r', label='samples') ax.plot(xdense, poly(xdense, betaHat, d), label='model') ax.set_ylim(-2, 2) ax.axis('off') ax.legend() ax.set_title('d=%d, MSE: Test=%.2f, Train=%.2f'% (d, mseos, mseois))
Code
# Create 2x2 subplot grid (all functions and variables are now persistent!)fig, axes = plt.subplots(2, 2, figsize=(12, 10))fig.suptitle('Double Descent Phenomenon: Polynomial Regression', fontsize=16)# Plot each degree in its respective subplotrun(1, axes[0, 0]) # Top leftrun(5, axes[0, 1]) # Top right run(20, axes[1, 0]) # Bottom leftrun(50, axes[1, 1]) # Bottom rightplt.tight_layout()plt.show()
Figure 20.4: Double Descent Phenomenon: Polynomial Regression with Different Degrees
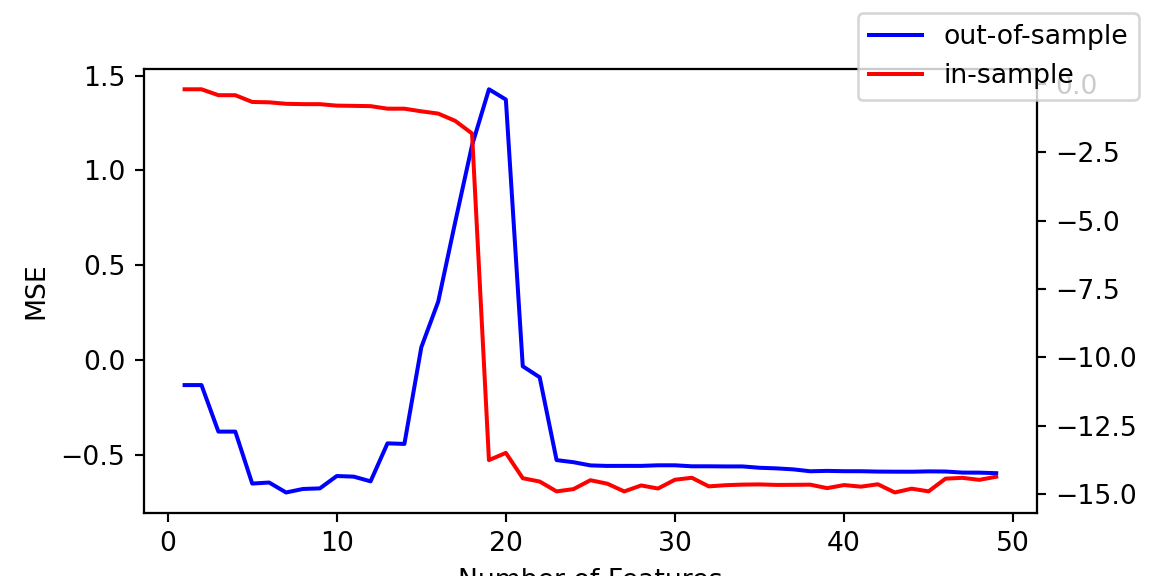
Now, let’s plot the MSE curve. We will plot the test error (blue line) and the training error (red line) for different polynomial degrees from 1 to 50.
Code
# Generate MSE data for different polynomial degrees (using persistent functions!)nd =50mse1 = np.zeros(nd) # Test MSEmse2 = np.zeros(nd) # Train MSEfor d inrange(1, nd): betaHat, mseos, mseois = fit(d) mse1[d] = mseos mse2[d] = mseoisfig, ax1 = plt.subplots()ax1.set_xlabel('Number of Features')ax1.set_ylabel('MSE', color='black')ax1.plot(np.log10(mse1), color='blue', label='out-of-sample')ax2 = ax1.twinx()ax2.plot(np.log10(mse2), color='red', label='in-sample')# plt.plot(mse1, label='out-of-sample')# plt.plot(mse2, label='in-sample')fig.legend()
Figure 20.5: Bias-Variance Trade-off: Training and Test MSE vs Model Complexity
The key insight from Figure 20.5 is the characteristic double descent shape in the test error (blue line). The curve exhibits three distinct phases:
Classical Regime: For low degrees (\(d < 5\)), increasing model complexity reduces both bias and test error, following the traditional understanding of the bias-variance tradeoff.
Interpolation Crisis: Around the interpolation threshold (\(d \approx n = 20\)), test error peaks dramatically as the model begins to perfectly fit the training data while generalizing poorly.
Over-parameterized Regime: For very high degrees (\(d > 30\)), test error decreases again, demonstrating that extreme over-parameterization can lead to improved generalization despite the model’s ability to memorize the training data.
This behavior challenges the conventional wisdom that more parameters necessarily lead to worse generalization. The double descent phenomenon arises from the implicit regularization effects of minimum-norm solutions in over-parameterized settings. When \(d > n\), the pseudoinverse solution corresponds to the minimum \(\ell_2\)-norm coefficients among all possible interpolating solutions. This implicit bias toward simpler functions can lead to surprisingly good generalization properties.
While this example uses polynomial regression for clarity, the double descent phenomenon has been observed across a wide range of modern machine learning models, including deep neural networks, random forests, and kernel methods. The implications for practice are significant. Given that model selection is time consuming and computationally expensive, this example shows, that instead of spending time to do model selection to find the “sweet spot” model with 5-degree polynomial, we just over-parametrise and get a good model for free!
This example serves as a concrete illustration of how classical statistical intuitions about model complexity may not apply in contemporary machine learning settings, particularly when dealing with over-parameterized models that have become increasingly common in practice.
20.9 Application
Simulated Data
We also apply the K-GAM architecture to a simulated dataset to evaluate its performance on data with known structure and relationships. The dataset contains 100 observations generated from the following function:
The goal is to predict the function \(y(x)\) based on the input \(x\). The dataset is often used as a benchmark dataset for regression algorithms due to its diverse mix of relationships (linear, quadratic, nonlinear, Gaussian random noise) between the input features and the target function.
We use the Koppen function to transform the five-dimensional input into a set of 11 features (\(2d+1\)). We then learn the outer function \(g\) using a ReLU network. To thoroughly investigate the model’s capabilities, we implement two distinct approaches to learning the outer function. The first approach uses different \(g\) functions for each feature, following the original KST formulation. This allows each function to specialize in capturing specific patterns, but might be more difficult to train and has more parameters. The second approach uses a single \(g\) function for all features, as proposed by Lorentz (1976), providing a more unified and parameter-efficient representation.
The first model with multiple \(g_i\) functions has dimensions: \(W^0_i \in \mathbb{R}^{16\times 1}\) and \(W^j_i \in \mathbb{R}^{16\times 16}\) for \(j=1,\ldots,18\).
The second architecture using single function \(g\) for all features maintains similar structure but increases inner layer width from 16 to 200. This increased capacity allows single functions to learn complex patterns, compensating for the constraint versus multiple specialized functions.
Training Rates
Consider nonparametric regression \(y_i= f (x_i) + \epsilon_i\) where \(x_i = ( x_{1i} , \ldots , x_{di} )\). We estimate \(f( x_1 , \ldots , x_d )\) for \(x = ( x_1 , \ldots , x_d ) \in [0,1]^d\). From a classical risk perspective:
\[
R ( f , \hat{f}_N ) = E_{X,Y} \left ( \lVert f - \hat{f}_N \rVert^2 \right ),
\] where \(\lVert \cdot \rVert\) denotes \(L^2(P_X)\)-norm.
Under standard assumptions, optimal minimax rate \(\inf_{\hat{f}} \sup_f R( f , \hat{f}_N ) = O_p ( N^{- 2 \beta /( 2 \beta + d )} )\) for \(\beta\)-Holder smooth functions \(f\). This rate depends on dimension \(d\), problematic in high dimensions. Restricting function classes yields better rates independent of \(d\), avoiding the curse of dimensionality. Common approaches include linear superpositions (ridge functions) and projection pursuit models.
Another asymptotic result comes from posterior concentration. Here, \(\hat{f}_N\) is a regularized MAP (maximum a posteriori) estimator solving:
where \(\phi(\hat{f})\) is regularization. Under appropriate conditions, posterior distribution \(\Pi(f | x, y)\) concentrates around true function at minimax rate (up to \(\log N\) factor).
A key result in the deep learning literature provides convergence rates for deep neural networks. Given a training dataset of input-output pairs \(( x_i , y_i)_{i=1}^N\) from the model \(y = f(x) + \epsilon\) where \(f\) is a deep learner (i.e. superposition of functions)
\[
f = g_L \circ \ldots g_1 \circ g_0
\]
where each \(g_i\) is a \(\beta_i\)-smooth Holder function with \(d_i\) variables, that is \(| g_i (x) -g_i (y) < | x-y |^\beta\).
This result can be applied to various function classes, including generalized additive models of the form
\[
f_0 ( x ) = h \left ( \sum_{p=1}^d f_{0,p} (x_p) \right )
\]
where \(g_0(z) = h(z)\), \(g_1 ( x_1 , \ldots , x_d ) = ( f_{01}(x_1) , \ldots , f_{0d} (x_d) )\) and \(g_2 ( y_1 , \ldots , y_d ) = \sum_{i=1}^d y_i\). In this case, \(d_1 = d_2 = 1\), and assuming \(h\) is Lipschitz, we get an optimal rate of \(O(N^{-1/3})\), which is independent of \(d\).
Schmidt-Hieber (2021) show that deep ReLU networks also have optimal rate of \(O( N^{-1/3} )\) for certain function classes. For \(3\)-times differentiable (e.g. cubic B-splines ), Coppejans (2004) finds a rate of \(O( N^{-3/7} ) = O( N^{-3/(2 \times 3 + 1) } )\). Igelnik and Parikh (2003) finds a rate \(O( N^{-1} )\) for Kolmogorov Spline Networks.
Finally, it’s worth noting the relationship between expected risk and empirical risk. The expected risk, \(R\), is typically bounded by the empirical risk plus a term of order \(1/\sqrt{N}\):
where \(f^\star\) is the minimizer of the expected risk. However, in the case of interpolation, where the model perfectly fits the training data, the empirical risk term becomes zero, leaving only the \(O(1/\sqrt{N})\) term.
20.10 Conclusion
This chapter has traced the theoretical foundations of deep learning through the lens of multivariate function approximation. Several key insights emerge from this analysis:
Mathematical Foundations: The Kolmogorov Superposition Theorem provides a rigorous theoretical basis for understanding why neural networks can approximate any continuous function. The theorem shows that any multivariate function can be decomposed into compositions of univariate functions—a principle that directly informs the layered architecture of modern neural networks.
Representation vs. Computation: While KST guarantees the existence of such representations, the inner functions (like the Koppen function) are typically non-smooth and computationally challenging. This highlights a fundamental tension: mathematically elegant representations may not always translate to efficient computation.
Connections Across Methods: We have seen deep connections between seemingly disparate approaches. Transformers can be understood as kernel smoothing methods. Deep networks perform sophisticated space partitioning similar to decision trees. The K-GAM framework reveals that deep learners are essentially generalized additive models with automatically learned features.
Double Descent and Over-parameterization: Perhaps most surprisingly, the double descent phenomenon suggests that classical intuitions about the bias-variance trade-off may not apply to modern over-parameterized models. Networks with more parameters than training examples can still generalize well, challenging conventional wisdom about model complexity.
These theoretical insights not only deepen our understanding of why deep learning works but also suggest new directions for developing more efficient and interpretable architectures. The ongoing research into Kolmogorov-Arnold Networks and related approaches hints at the possibility of achieving the representational power of deep learning with potentially simpler, more interpretable structures.
Actor, Jonas. 2018. “Computation for the Kolmogorov Superposition Theorem.” {{MS Thesis}}, Rice.
Bach, Francis. 2024. “High-Dimensional Analysis of Double Descent for Linear Regression with Random Projections.”SIAM Journal on Mathematics of Data Science 6 (1): 26–50.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. “Neural Machine Translation by Jointly Learning to Align and Translate.” arXiv. https://arxiv.org/abs/1409.0473.
Belkin, Mikhail, Daniel Hsu, Siyuan Ma, and Soumik Mandal. 2019. “Reconciling Modern Machine-Learning Practice and the Classical Bias–Variance Trade-Off.”Proceedings of the National Academy of Sciences 116 (32): 15849–54.
Braun, Heinrich, and Martin Riedmiller. 2009. “Constructive Neural Network Learning Algorithms for Pattern Classification.”IEEE Transactions on Neural Networks 20 (1): 84–97.
Brillinger, David R. 2012. “A Generalized Linear Model With‘Gaussian’Regressor Variables.” In Selected Works of David Brillinger, edited by Peter Guttorp and David Brillinger, 589–606. Selected Works in Probability and Statistics. New York, NY: Springer.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.”Advances in Neural Information Processing Systems 33: 1877–1901.
Coppejans, Mark. 2004. “On Kolmogorov’s Representation of Functions of Several Variables by Functions of One Variable.”Journal of Econometrics 123 (1): 1–31.
Dembo, Amir. 2021. “A Note on the Universal Approximation Capability of Deep Neural Networks.”arXiv Preprint arXiv:2104.xxxxx.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–86. Minneapolis, Minnesota: Association for Computational Linguistics.
Diaconis, Persi, and Mehrdad Shahshahani. 1984. “On Nonlinear Functions of Linear Combinations.”SIAM Journal on Scientific and Statistical Computing 5 (1): 175–91.
Dixon, Matthew F, Nicholas G Polson, and Vadim O Sokolov. 2019. “Deep Learning for Spatio-Temporal Modeling: Dynamic Traffic Flows and High Frequency Trading.”Applied Stochastic Models in Business and Industry 35 (3): 788–807.
Fredholm, Ivar. 1903. “Sur Une Classe d’équations Fonctionnelles.”Acta Mathematica 27 (none): 365–90.
Friedman, Jerome H., and Werner Stuetzle. 1981. “Projection Pursuit Regression.”Journal of the American Statistical Association 76 (376): 817–23.
Hastie, Trevor, Andrea Montanari, Saharon Rosset, and Ryan J. Tibshirani. 2022. “Surprises in High-Dimensional Ridgeless Least Squares Interpolation.”The Annals of Statistics 50 (2): 949–86.
Huber, Peter J. 1985. “Projection Pursuit.”The Annals of Statistics 13 (2): 435–75.
Igelnik, B., and N. Parikh. 2003. “Kolmogorov’s Spline Network.”IEEE Transactions on Neural Networks 14 (4): 725–33.
Kaczmarz, Stefan. 1937. “Angenäherte Auflösung von Systemen Linearer Gleichungen.”Bulletin International de l’Académie Polonaise Des Sciences Et Des Lettres 35: 355–57.
Kolmogorov, AN. 1956. “On the Representation of Continuous Functions of Several Variables as Superpositions of Functions of Smaller Number of Variables.” In Soviet. Math. Dokl, 108:179–82.
Köppen, Mario. 2000. “The Curse of Dimensionality.”5th Online World Conference on Soft Computing in Industrial Applications (WSC5) 1: 4–8.
Lin, Zhouhan, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 2017. “A Structured Self-attentive Sentence Embedding.” arXiv. https://arxiv.org/abs/1703.03130.
Lorentz, George G. 1976. “The 13th Problem of Hilbert.” In Proceedings of Symposia in Pure Mathematics, 28:419–30. American Mathematical Society.
Nadaraya, E. A. 1964. “On Estimating Regression.”Theory of Probability & Its Applications 9 (1): 141–42.
Nakkiran, Preetum, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. 2021. “Deep Double Descent: Where Bigger Models and More Data Hurt*.”Journal of Statistical Mechanics: Theory and Experiment 2021 (12): 124003.
Nareklishvili, Maria, Nicholas Polson, and Vadim Sokolov. 2023. “Generative Causal Inference,” June. https://arxiv.org/abs/2306.16096.
Polson, Nicholas G, Vadim Sokolov, et al. 2017. “Deep Learning: A Bayesian Perspective.”Bayesian Analysis 12 (4): 1275–1304.
Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.”Journal of Machine Learning Research 21 (140): 1–67.
Sprecher, David A. 1965. “On the Structure of Continuous Functions of Several Variables.”Transactions of the American Mathematical Society 115: 340–55.
Tsai, Yao-Hung Hubert, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. “Transformer Dissection: A Unified Understanding of Transformer’s Attention via the Lens of Kernel.” arXiv. https://arxiv.org/abs/1908.11775.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. “Attention Is All You Need.” arXiv. https://arxiv.org/abs/1706.03762.
Watson, Geoffrey S. 1964. “Smooth Regression Analysis.”Sankhyā: The Indian Journal of Statistics, Series A (1961-2002) 26 (4): 359–72.