The ability to understand and generate human language has long been considered a hallmark of intelligence. When Alan Turing proposed his famous test in 1950, he chose natural conversation as the ultimate benchmark for machine intelligence. Yet for decades, this goal remained frustratingly elusive. Early attempts at machine translation in the 1950s, which simply replaced words using bilingual dictionaries, produced nonsensical results that highlighted the profound complexity of human language. The phrase “The spirit is willing, but the flesh is weak” allegedly translated to Russian and back as “The vodka is good, but the meat is rotten”—a cautionary tale about the subtleties of meaning that transcend mere word substitution.
This chapter traces the remarkable journey from those early failures to today’s language models that can engage in nuanced dialogue, translate between languages with near-human accuracy, and even generate creative text. At the heart of this transformation lies a fundamental shift in how we represent language computationally: from discrete symbols manipulated by hand-crafted rules to continuous vector spaces learned from vast corpora of text.
The chapter develops the mathematical foundations of natural language understanding. We begin with word embeddings—continuous vector representations that encode semantic relationships. We then introduce attention mechanisms that enable context-dependent representations, culminating in the Transformer architecture that powers modern language models like BERT and GPT.
23.1 Converting Words to Numbers (Embeddings)
Language poses distinctive challenges for mathematical modeling: unlike images, which naturally exist as arrays of continuous pixel values, or audio signals, which are continuous waveforms, text consists of discrete symbols with no inherent geometric structure. The word “cat” is not inherently closer to “dog” than to “quantum”—at least not in any obvious mathematical sense. Yet humans effortlessly recognize that cats and dogs share semantic properties that neither shares with abstract physics concepts.
A naive way to represent words is through one-hot encoding, where each word in a vocabulary is assigned a unique vector with a single non-zero entry. For example, in a vocabulary of size \(|V|\), the word “cat” might be represented as \[
v_{\text{cat}} = \overbrace{[0, 0, \ldots, 1, \ldots, 0]}^{|V|}
\] with the 1 in the \(i\)-th position corresponding to “cat”. However, this approach fails to capture any notion of semantic similarity: the cosine similarity between any two distinct one-hot vectors is zero, erasing all information about how words relate to each other.
This type of representation makes even the seemingly simple task of determining whether two sentences have similar meanings challenging. The sentences “The cat sat on the mat” and “A feline rested on the rug” express nearly identical ideas despite sharing no words except “the” and “on.” Conversely, “The bank is closed” could refer to a financial institution or a river’s edge—the same words encoding entirely different meanings. These examples illustrate why early symbolic approaches to natural language processing, based on logical rules and hand-crafted features, struggled to capture the fluid, contextual nature of meaning.
The breakthrough came from reconceptualizing the representation problem. Instead of treating words as atomic symbols, what if we could embed them in a continuous vector space where geometric relationships encode semantic relationships? This idea, simple in retrospect, revolutionized the field. In such a space, we might find that \(v_{\text{cat}} - v_{\text{dog}}\) has similar direction to \(v_{\text{car}} - v_{\text{bicycle}}\), capturing the analogical relationship “cat is to dog as car is to bicycle” through vector arithmetic.
To formalize this intuition, we seek a mapping \(\phi: \mathcal{V} \rightarrow \mathbb{R}^d\) from a vocabulary \(\mathcal{V}\) of discrete tokens to \(d\)-dimensional vectors. The challenge lies in learning this mapping such that the resulting geometry reflects semantic relationships.
The Math of Twenty Questions
My (Vadim’s) daughter and I play a game of Twenty Questions during road trips. The rules are simple: one person thinks of something, and the other person has to guess what it is by asking yes-or-no questions. The person who is guessing can ask up to twenty questions, and then they have to make a guess. If they guess correctly, they win; if not, the other person wins. The game is fun, but it’s also a great way to illustrate how AI systems can learn to represent words and phrases as numbers. The trick is to come up with an optimal set of yes-or-no questions that will allow you to distinguish between all the words or phrases you might want to represent. Surprisingly, most of the words can be identified with a small set of universal questions asked in the same order every time. Usually the person who has a better set of questions wins. For example, you might ask:
Is it an animal? (Yes)
Is this a domestic animal? (No)
Is it larger than a human? (Yes)
Does it have a long tail? (No)
Is it a predator? (Yes)
Can move on two feet? (Yes)
Is it a bear? (Yes)
Thus, if we use a 20-dimensional 0-1 vector to represent the word “bear,” the portion of this vector corresponding to these questions would look like this:
Animal
Domestic
Larger than human
Long tail
Predator
Can move on two feet
Bear
1
0
1
0
1
1
This is called a word vector. Specifically, it’s a “binary” or 0/1 vector: 1 means yes, 0 means no. Different words would produce different answers to the same questions, so they would have different word vectors. If we stack all these vectors in a matrix, where each row is a word and each column is a question, we get something like this:
Animal
Domestic
Larger than human
Long tail
Predator
Can move on two feet
Bear
1
0
1
0
1
1
Dog
1
1
0
1
0
0
Cat
1
1
0
1
1
0
The binary nature of these vectors forces us to choose 1 or 0 for the “Larger than human” question for “Dog.” However, there are some dog breeds that are larger than humans, so this binary representation is not very useful in this case. We can do better by allowing the answers to be numbers between 0 and 1, rather than just 0 or 1. This way, we can represent the fact that some dogs are larger than humans, but most are not. For example, we might answer the question “Is it larger than a human?” with a 0.1 for a dog and a 0.8 for a bear. Some types of bears can be smaller than humans, for example, black bears that live in North America, but most bears are larger than humans.
Using this approach, the vectors now become
Animal
Domestic
Larger than human
Long tail
Predator
Can move on two feet
Bear
1
0
0.8
0
1
0.8
Dog
1
1
0.1
0.6
0
0
Cat
1
0.7
0.01
1
0.6
0
AI systems also use non-binary scoring rules to judge a win or loss. For example, if the answer is “bear,” then the score might be 100 points for a correct guess, 90 points for a close guess like “wolf” or “lion,” and 50 points for a distant guess like “eagle.” This way of keeping score matches the real-world design requirements of most NLP systems. For example, if you translate JFK saying “Ich bin ein Berliner” as “I am a German,” you’re wrong, but a lot closer than if you translate it as “I am a butterfly.”
The process of converting words into numbers is called “embedding.” The resulting vectors are called “word embeddings.” The only part that is left is how to design an algorithm that can find a good set of questions to ask. Usually real-life word embeddings have hundreds of questions, not just twenty. The process of finding these questions is called “training” the model. The goal is to find a set of questions that will allow the model to distinguish between all the words in the vocabulary, and to do so in a way that captures their meanings. However, the algorithms do not have a notion of meaning in the same way that humans do. Instead, they learn by counting word co-location statistics—that is, which words tend to appear with which other words in real sentences written by humans.
These co-occurrence statistics serve as surprisingly effective proxies for meaning. For example, consider the question: “Among all sentences containing ‘fries’ and ‘ketchup,’ how frequently does the word ‘bun’ also appear?” This is the kind of query a machine can easily formulate and answer, since it relies on counting rather than true understanding.
While such a specific question may be too limited if you can only ask a few hundred, the underlying idea—using word co-occurrence patterns—is powerful. Word embedding algorithms are built on this principle: they systematically explore which words tend to appear together, and through optimization, learn the most informative “questions” to ask. By repeatedly applying these learned probes, the algorithms construct a vector for each word or phrase, capturing its relationships based on co-occurrence statistics. These word vectors are then organized into a matrix for further use.
There are many ways to train word embeddings, but the most common one is to use a neural network. The neural network learns to ask questions that are most useful for distinguishing between different words. It does this by looking at a large number of examples of words and their meanings, and then adjusting the weights of the questions based on how well they perform. One of the first and most popular algorithms for this is called Word2Vec, which was introduced by Mikolov et al. (2013) at Google in 2013.
23.2 Word2Vec and Distributional Semantics
The theoretical foundation for learning meaningful word representations comes from the distributional hypothesis, articulated by linguist J.R. Firth in 1957: “You shall know a word by the company it keeps.” This principle suggests that words appearing in similar contexts tend to have similar meanings. If “coffee” and “tea” both frequently appear near words like “drink,” “hot,” “cup,” and “morning,” we can infer their semantic similarity.
The word2vec framework, introduced by Mikolov et al. (2013), operationalized this insight through a beautifully simple probabilistic model. The skip-gram variant posits that a word can be used to predict its surrounding context words. Given a corpus of text represented as a sequence of words \(w_1, w_2, \ldots, w_T\), the model maximizes the likelihood:
where \(m\) is the context window size. The conditional probability is parameterized using two sets of embeddings: \(\mathbf{v}_w\) for words as centers and \(\mathbf{u}_w\) for words as context:
This formulation reveals deep connections to the theoretical frameworks discussed in previous chapters. The dot product \(\mathbf{u}_o^T \mathbf{v}_c\) acts as a compatibility score between center and context words, while the softmax normalization ensures a valid probability distribution. From the perspective of ridge functions, we can view this as learning representations where the function \(f(w_c, w_o) = \mathbf{u}_o^T \mathbf{v}_c\) captures the log-odds of co-occurrence.
23.3 Word2Vec for War and Peace
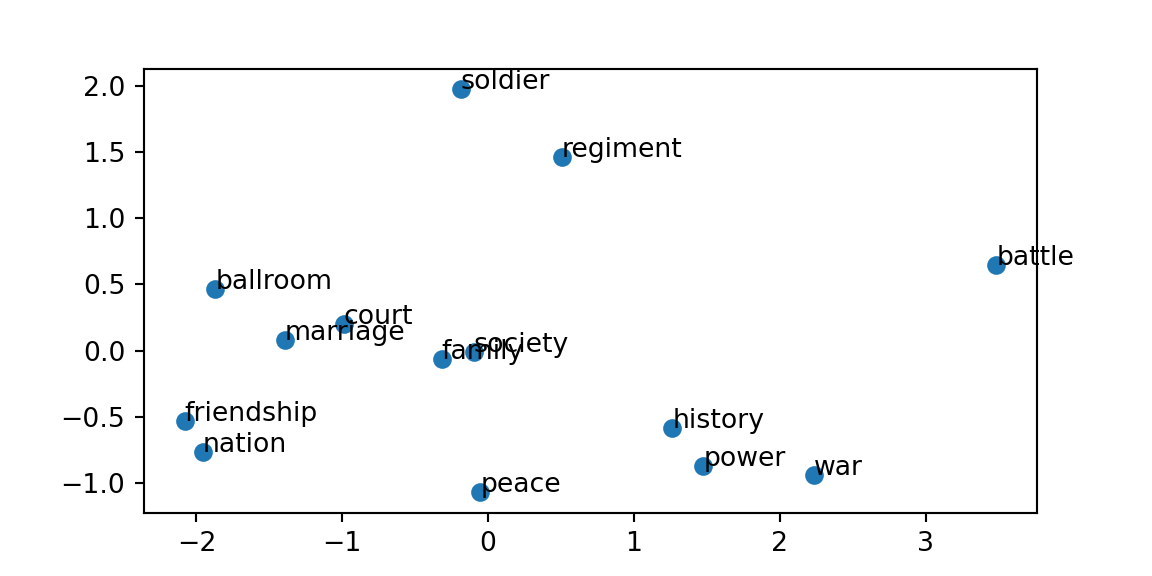
This analysis showcases the application of Word2Vec on Leo Tolstoy’s “War and Peace,” demonstrating how neural network-based techniques can learn vector representations of words by analyzing their contextual relationships within the text. The model employs the skip-gram algorithm with negative sampling (explained later), a widely used configuration for Word2Vec. We use vector dimension of 100, providing a balance between capturing semantic detail and computational efficiency. The context window size is set to 5, and the model is trained over several iterations to ensure convergence. Finally, we use PCA to reduce the dimensionality of the vectors to 2D for visualization.
Word2Vec for War and Peace
from gensim.models import Word2Vecfrom sklearn.decomposition import PCAfrom matplotlib import pyplot# define training data, read from ../data/warpeace.txtwithopen('../data/warpeace.txt', 'r') asfile: Text =file.read()sentences = [s.split() for s in Text.split('. ') ] # split the text into sentences# Remove spaces and punctuationsentences = [[word.strip('.,!?;:()[]') for word in sentence if word.strip('.,!?;:()[]')] for sentence in sentences]# Remove empty sentencessentences = [sentence for sentence in sentences if sentence]model = Word2Vec(sentences, min_count=1,seed=42,workers=1)# fit a 2d PCA model to the vectors, only use the words from ../data/embedding_words.txtwithopen('../data/embedding_words.txt', 'r') asfile: words =file.read().splitlines()X = model.wv[words] # get the vectors for the words# reduce the dimensionality of the vectors to 2D using PCApca = PCA(n_components=2)result = pca.fit_transform(X)# create a scatter plot of the projectionpyplot.scatter(result[:, 0], result[:, 1])# words = model.wv.index_to_keyfor i, word inenumerate(words): pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))pyplot.show()
Word2Vec for War and Peace
The results reveal meaningful semantic relationships within the text and highlight several key insights into the thematic structure of Tolstoy’s War and Peace. First, the clustering of military-related terms (soldier, regiment, battle) underscores Word2Vec’s ability to group semantically related words based on their co-occurrence patterns. Additionally, the grouping of words such as “ballroom,” “court,” and “marriage” reflects the novel’s emphasis on aristocratic society and its social hierarchy. The use of PCA for dimensionality reduction effectively preserves meaningful relationships while reducing the original high-dimensional Word2Vec space (100 dimensions) to a two-dimensional representation. Overall, this visualization demonstrates how Word2Vec captures distinct thematic domains, including military, social, and government. Notice that a more abstract concept like peace is surrounded by words from both government (history, power, war) and social domains (family, friendship, marriage,court, ballroom, society), indicating its central role in the narrative but is distant from the military domain, which is more focused on the war aspect of the story.
These insights have practical applications in literary analysis, theme extraction, character relationship mapping, historical text understanding, and similarity-based text search and recommendation systems.
The Skip-Gram Model
The skip-gram model operates on a simple yet powerful principle: given a center word, predict the surrounding context words within a fixed window. This approach assumes that words appearing in similar contexts tend to have similar meanings, directly implementing the distributional hypothesis.
Consider the sentence “The man loves his son” with “loves” as the center word and a context window of size 2. The skip-gram model aims to maximize the probability of generating the context words “the,” “man,” “his,” and “son” given the center word “loves.” This relationship can be visualized as follows:
graph TD
A[loves] --> B[the]
A --> C[man]
A --> D[his]
A --> E[son]
style A fill:#e1f5fe
style B fill:#f3e5f5
style C fill:#f3e5f5
style D fill:#f3e5f5
style E fill:#f3e5f5
classDef centerWord fill:#e1f5fe,stroke:#0277bd,stroke-width:2px
classDef contextWord fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
class A centerWord
class B,C,D,E contextWord
The mathematical foundation assumes conditional independence among context words given the center word, allowing the joint probability to factorize:
This independence assumption, while not strictly true in natural language, proves crucial for computational tractability. Each conditional probability is modeled using the softmax function over the entire vocabulary:
The skip-gram objective seeks to maximize the likelihood of observing all context words across the entire corpus. For a text sequence of length \(T\) with words \(w^{(1)}, w^{(2)}, \ldots, w^{(T)}\), the objective becomes:
This elegant form shows that the gradient pushes the center word embedding toward the observed context word (\(\mathbf{u}_o\)) while pulling it away from all other words, weighted by their predicted probabilities. This creates a natural contrast between positive and negative examples, even in the original formulation without explicit negative sampling.
The skip-gram architecture assigns two vector representations to each word: \(\mathbf{v}_w\) when the word serves as a center word and \(\mathbf{u}_w\) when it appears in context. This asymmetry allows the model to capture different aspects of word usage. After training, the center word vectors \(\mathbf{v}_w\) are typically used as the final word embeddings, though some implementations average or concatenate both representations.
The Continuous Bag of Words (CBOW) Model
While skip-gram predicts context words from a center word, the Continuous Bag of Words (CBOW) model reverses this relationship: it predicts a center word based on its surrounding context. For the same text sequence “the”, “man”, “loves”, “his”, “son” with “loves” as the center word, CBOW models the conditional probability:
The CBOW architecture can be visualized as multiple context words converging to predict a single center word:
graph TD
B[the] --> A[loves]
C[man] --> A
D[his] --> A
E[son] --> A
style A fill:#e1f5fe
style B fill:#f3e5f5
style C fill:#f3e5f5
style D fill:#f3e5f5
style E fill:#f3e5f5
classDef centerWord fill:#e1f5fe,stroke:#0277bd,stroke-width:2px
classDef contextWord fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
class A centerWord
class B,C,D,E contextWord
The key difference from skip-gram lies in how CBOW handles multiple context words. Rather than treating each context word independently, CBOW averages their embeddings. For a center word \(w_c\) with context words \(w_{o_1}, \ldots, w_{o_{2m}}\), the conditional probability is:
where \(\bar{\mathbf{v}}_o = \frac{1}{2m}\sum_{j=1}^{2m} \mathbf{v}_{o_j}\) is the average of context word vectors. Note that in CBOW, \(\mathbf{u}_i\) represents word \(i\) as a center word and \(\mathbf{v}_i\) represents it as a context word—the opposite of skip-gram’s convention.
The CBOW objective maximizes the likelihood of generating all center words given their contexts:
This gradient is scaled by \(\frac{1}{2m}\), effectively distributing the learning signal across all context words. CBOW tends to train faster than skip-gram because it predicts one word per context window rather than multiple words, but skip-gram often produces better representations for rare words since it generates more training examples per sentence.
Pretraining Word2Vec
Training word2vec models requires careful attention to implementation details that significantly impact the quality of learned representations. The training process begins with data preprocessing on large text corpora. Using the Penn Tree Bank dataset as an example—a carefully annotated corpus of Wall Street Journal articles containing about 1 million words—we implement several crucial preprocessing steps.
First, we build a vocabulary by counting word frequencies and retaining only words that appear at least a minimum number of times (typically 5-10). This thresholding serves two purposes: it reduces the vocabulary size from potentially millions to tens of thousands of words, and it prevents the model from wasting capacity on rare words that appear too infrequently to learn meaningful representations. Words below the threshold are replaced with a special <unk> token.
The training procedure uses stochastic gradient descent with a carefully designed learning rate schedule. The initial learning rate (typically 0.025 for skip-gram and 0.05 for CBOW) is linearly decreased to a minimum value (usually 0.0001) as training progresses:
This schedule ensures larger updates early in training when representations are poor, transitioning to fine-tuning as the model converges.
The implementation uses several optimizations for efficiency. Word vectors are typically initialized randomly from a uniform distribution over \([-0.5/d, 0.5/d]\) where \(d\) is the embedding dimension (commonly 100-300). During training, we maintain two embedding matrices: one for center words and one for context words. After training, these can be combined (usually by averaging) or just the center word embeddings can be used.
For minibatch processing, training examples are grouped to enable efficient matrix operations. Given a batch of center-context pairs, the forward pass computes scores using matrix multiplication, applies the loss function (either full softmax, hierarchical softmax, or negative sampling), and backpropagates gradients. A typical training configuration might process batches of 512 word pairs, iterating 5-15 times over a corpus.
The quality of learned embeddings can be evaluated through word similarity and analogy tasks. For similarity, we compute cosine distances between word vectors and verify that semantically similar words have high cosine similarity. For analogies, we test whether vector arithmetic captures semantic relationships: the famous “king - man + woman \(\approx\) queen” example demonstrates that vector differences encode meaningful semantic transformations.
A crucial but often overlooked aspect is subsampling of frequent words. Words like “the,” “a,” and “is” appear so frequently that they provide little information about the semantic content of their neighbors. The probability of discarding a word \(w\) during training is:
where \(f(w)\) is the frequency of word \(w\) and \(t\) is a threshold (typically \(10^{-5}\)). This formula ensures that very frequent words are aggressively subsampled while preserving most occurrences of informative words.
For training, we extract examples by sliding a window over the text. For each center word, we collect its context words within a window of size \(m\). Importantly, the actual window size is sampled uniformly from \([1, m]\) for each center word, which helps the model learn representations that are robust to varying context sizes. Consider the sentence “the cat sat on the mat” with maximum window size 2. For the center word “sat,” we might sample a window size of 1, giving context words [“cat”, “on”], or a window size of 2, giving context words [“the”, “cat”, “on”, “the”].
23.4 Computational Efficiency Through Negative Sampling
The elegance of word2vec’s formulation belies a serious computational challenge. Computing the normalization term in the softmax requires summing over the entire vocabulary—potentially millions of terms—for every gradient update. With large corpora containing billions of words, this quickly becomes intractable.
Negative sampling transforms the problem from multi-class classification to binary classification. Instead of predicting which word from the entire vocabulary appears in the context, we ask a simpler question: given a word pair, is it a real center-context pair from the corpus or a randomly generated negative example? The objective becomes:
where \(\sigma(x) = 1/(1 + e^{-x})\) is the sigmoid function, and \(P_n\) is a noise distribution over words. The clever insight is that by carefully choosing the noise distribution—typically \(P_n(w) \propto f(w)^{3/4}\) where \(f(w)\) is word frequency—we can approximate the original objective while reducing computation from \(O(|\mathcal{V}|)\) to \(O(K)\), where \(K \ll |\mathcal{V}|\) is a small number of negative samples (typically 5-20).
An alternative solution is hierarchical softmax, which replaces the flat softmax over the vocabulary with a binary tree where each leaf represents a word. The probability of a word is then the product of binary decisions along the path from root to leaf:
where \(L(w_o)\) is the length of the path to word \(w_o\), \(n(w_o, j)\) is the \(j\)-th node on this path, and \([\![\cdot]\!]\) is the Iverson bracket—a notation that returns \(+1\) if the condition inside is true (the next node is the left child) and \(-1\) otherwise (the next node is the right child). This sign flip determines whether we use the sigmoid or its complement at each binary decision. Hierarchical softmax reduces computational complexity from \(O(|\mathcal{V}|)\) to \(O(\log |\mathcal{V}|)\), though negative sampling typically performs better in practice.
23.5 Global Vectors and Matrix Factorization
While word2vec learns from local context windows, GloVe (Global Vectors) leverages global co-occurrence statistics. The key observation is that the ratio of co-occurrence probabilities can encode semantic relationships. Consider the words “ice” and “steam” in relation to “solid” and “gas”: \(P(\text{solid} \mid \text{ice}) / P(\text{solid} \mid \text{steam})\) is large (around 8.9), while \(P(\text{gas} \mid \text{ice}) / P(\text{gas} \mid \text{steam})\) is small (around 0.085), and \(P(\text{water} \mid \text{ice}) / P(\text{water} \mid \text{steam})\) is close to 1 (around 1.36).
These ratios capture the semantic relationships: ice is solid, steam is gas, and both relate to water. GloVe learns embeddings that preserve these ratios through the objective:
where \(X_{ij}\) counts co-occurrences, \(h(\cdot)\) is a weighting function that prevents very common or very rare pairs from dominating, and \(b_i, c_j\) are bias terms. A typical choice is \(h(x) = (x/x_{\max})^{\alpha}\) if \(x < x_{\max}\), else 1, with \(\alpha = 0.75\) and \(x_{\max} = 100\).
This formulation reveals GloVe as a weighted matrix factorization problem. We seek low-rank factors \(\mathbf{V}\) and \(\mathbf{U}\) such that \(\mathbf{V}^T\mathbf{U} \approx \log \mathbf{X}\), where the approximation is weighted by the function \(h(\cdot)\). This connection to classical linear algebra provides theoretical insights: the optimal embeddings lie in the subspace spanned by the top singular vectors of an appropriately transformed co-occurrence matrix.
23.6 Beyond Words: Subword and Character Models (Tokenization)
A fundamental limitation of word-level embeddings is their inability to handle out-of-vocabulary words or capture morphological relationships. The word “unhappiness” shares obvious morphological connections with “happy,” “unhappy,” and “happiness,” but word2vec treats these as completely independent tokens.
FastText addresses this limitation by representing words as bags of character n-grams. For the word “where” with n-grams of length 3 to 6, we extract: “<wh”, “whe”, “her”, “ere”, “re>”, and longer n-grams up to the full word. The word embedding is then the sum of its n-gram embeddings:
This approach naturally handles out-of-vocabulary words by breaking them into known n-grams and provides better representations for rare words by sharing parameters across morphologically related words.
An even more flexible approach is Byte Pair Encoding (BPE), which learns a vocabulary of subword units directly from the data. Starting with individual characters, BPE iteratively merges the most frequent pair of adjacent units until reaching a desired vocabulary size. For example, given a corpus with word frequencies {“fast”: 4, “faster”: 3, “tall”: 5, “taller”: 4}, BPE might learn merges like “t” + “a” \(\rightarrow\) “ta”, then “ta” + “l” \(\rightarrow\) “tal”, and so on. This data-driven approach balances vocabulary size with representation power, enabling models to handle arbitrary text while maintaining reasonable computational requirements.
The choice of tokenization strategy has profound implications for model performance and behavior. Modern LLMs typically use vocabularies of 50,000 to 100,000 tokens, carefully balanced to represent different languages while maintaining computational efficiency. A vocabulary that’s too small forces the model to represent complex concepts with many tokens, making it harder to capture meaning efficiently.
Consider how the sentence “The Verbasizer helped Bowie create unexpected word combinations” might be tokenized by a BPE-based system. Rather than treating each word as a single unit, the tokenizer might split it into subword pieces like [“The”, ” Ver”, “bas”, “izer”, ” helped”, ” Bow”, “ie”, ” create”, ” unexpected”, ” word”, ” combinations”]. This fragmentation allows the model to handle rare words and proper names by breaking them into more common subcomponents.
This tokenization process explains some behavioral patterns in modern language models. Names from fictional universes, specialized terminology, and code snippets can be tokenized in ways that fragment their semantic meaning, potentially affecting model performance on these inputs. Understanding these tokenization effects is crucial for interpreting model behavior and designing effective prompting strategies.
23.7 Attention Mechanisms and Contextual Representations
Static word embeddings suffer from a fundamental limitation: they assign a single vector to each word, ignoring context. The word “bank” receives the same representation whether it appears in “river bank” or “investment bank.” This conflation of multiple senses into a single vector creates an information bottleneck that limits performance on downstream tasks.
The evolution of word embeddings culminated in the development of contextual representations, which dynamically adjust based on surrounding context. The context problem was solved by the introduction of attention mechanisms, particularly in the transformer architecture, which allows models to capture complex dependencies and relationships between words. The idea is to mimic the human ability to selectively focus attention. When reading this sentence, your visual system processes every word simultaneously, yet your conscious attention flows sequentially from word to word. You can redirect this attention at will—perhaps noticing a particular phrase or jumping back to reread a complex clause. This dynamic allocation of cognitive resources allows us to extract meaning from information-rich environments without being overwhelmed by irrelevant details.
Machine learning systems faced analogous challenges in processing sequential information. Early neural networks, particularly recurrent architectures, processed sequences step by step, maintaining a hidden state that theoretically encoded all previous information. However, this sequential bottleneck created fundamental limitations: information from early time steps could vanish as sequences grew longer, and the inherently sequential nature prevented parallel computation that could leverage modern hardware effectively.
The attention Vaswani et al. (2023) mechanism revolutionized this landscape by allowing models to directly access and combine information from any part of the input sequence. Rather than compressing an entire sequence into a fixed-size vector, attention mechanisms create dynamic representations that adaptively weight different parts of the input based on their relevance to the current computation. This breakthrough enabled the development of the Transformer architecture, which forms the foundation of modern language models from BERT to GPT.
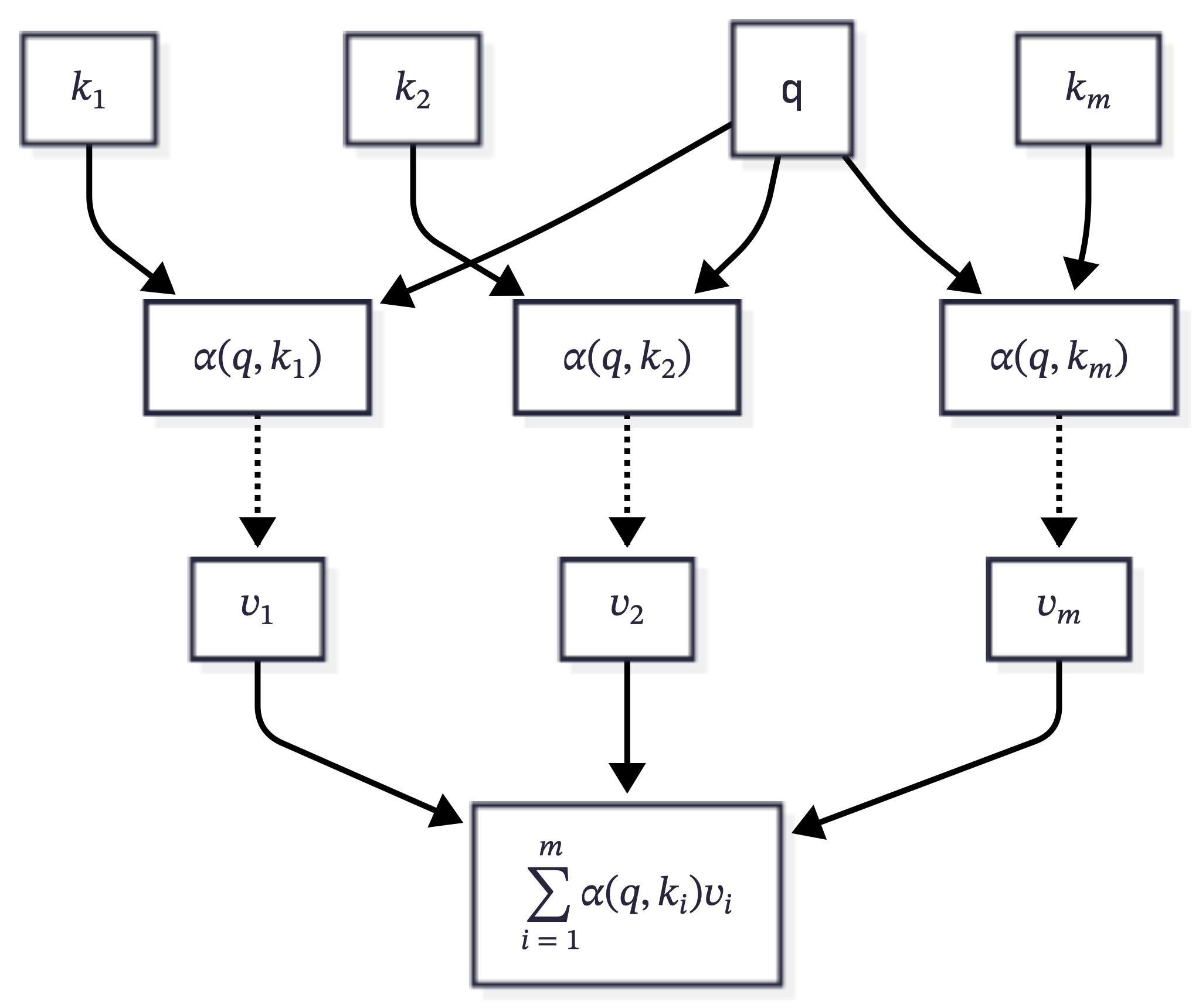
At its core, attention implements an information retrieval system inspired by database operations. Consider how you might search through a library: you formulate a query (what you’re looking for), examine the keys (catalog entries or book titles), and retrieve the associated values (the actual books or their contents). Attention mechanisms formalize this intuition through three learned representations:
Queries (\(\mathbf{Q}\)): What information are we seeking?
Keys (\(\mathbf{K}\)): What information is available at each position?
Values (\(\mathbf{V}\)): What information should we retrieve?
Given a set of keys and values, attention computes a weighted sum of the values based on their relevance to the query. Mathematically, this can be expressed as: \[
\textrm{Attention}(\mathbf{q}) \stackrel{\textrm{def}}{=} \sum_{i=1}^m \alpha_i(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i,
\]
where \(\alpha_i\) are scalar attention weights computed from the queries and keys. The operation itself is typically referred to as attention pooling. The name “attention” derives from the fact that the operation pays particular attention to the terms for which the weight \(\alpha_i\) is significant (i.e., large).
It is typical in AI applications to assume that the attention weights \(\alpha_i\) are nonnegative and form a convex combination, i.e., \(\sum_{i=1}^n \alpha_i = 1\). A common strategy for ensuring that the weights sum up to 1 is to normalize the unnormalized scores \(s_i\) via the softmax function: \[
\alpha_i = \frac{\exp(s_i)}{\sum_{j=1}^n \exp(s_j)}
\]
23.8 Kernel Smoothing as Attention
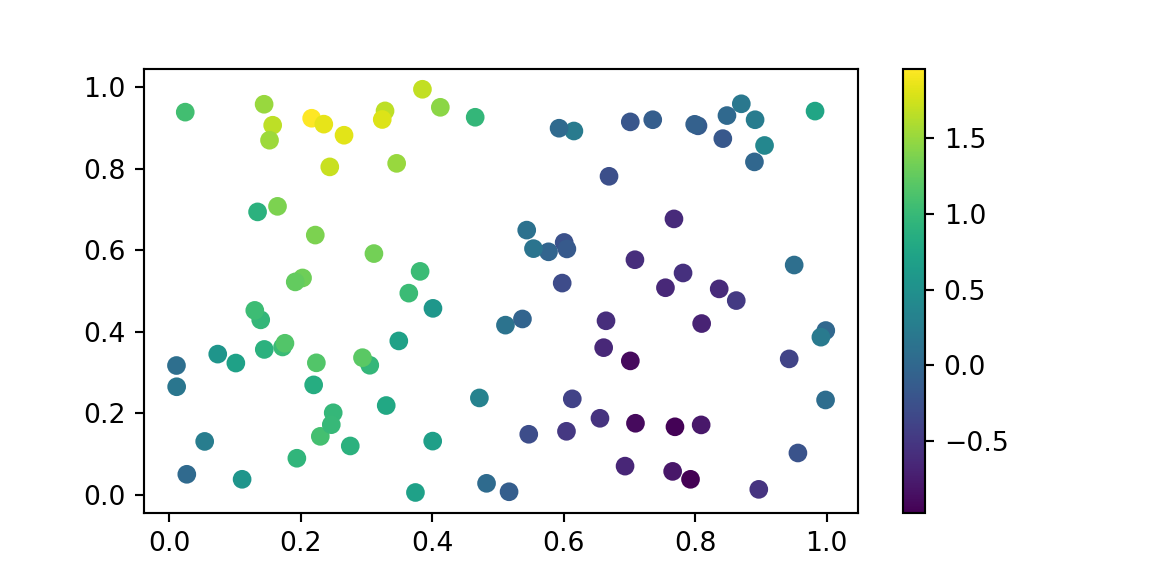
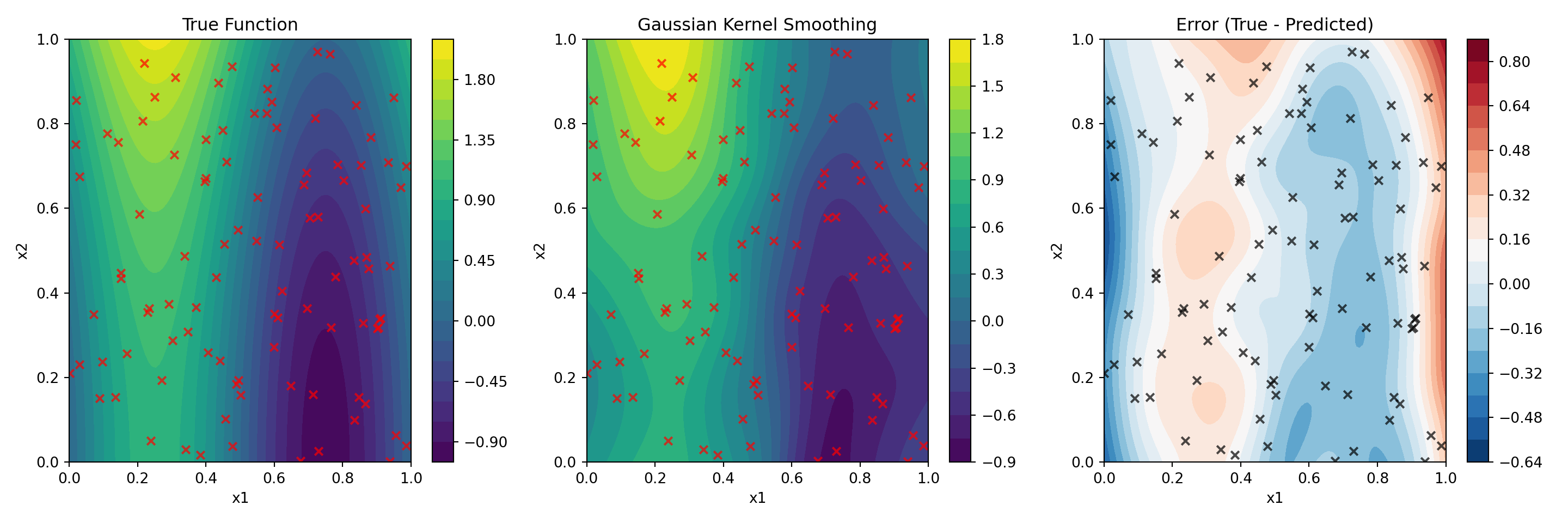
The concept of attention pooling can actually be traced back to classical kernel methods like Nadaraya-Watson regression, where similarity kernels determine how much weight to give to different data points. Given a sequence of observations \(y_1, \ldots, y_n\), and each observation has a two-dimensional index \(x^{(i)} \in \mathbb{R}^2\), such as in a spatial process. Then the question is what would be the value of \(y\) at a previously unobserved location \(x_{new} = (x_1,x_2)\). Let’s simulate some data and see what we can do.
The kernel smoothing method then uses \(q = (x_1,x_2)\) as the query and observed \(x_i\)s as the keys. The weights are then computed as \(\alpha_i = K(q, x_i)\) where \(K\) is a kernel function, that measures, how close \(q\) is to \(x_i\). Then, our prediction would be \[
\hat{y} = \sum_{i=1}^n \alpha_i y_i.
\]
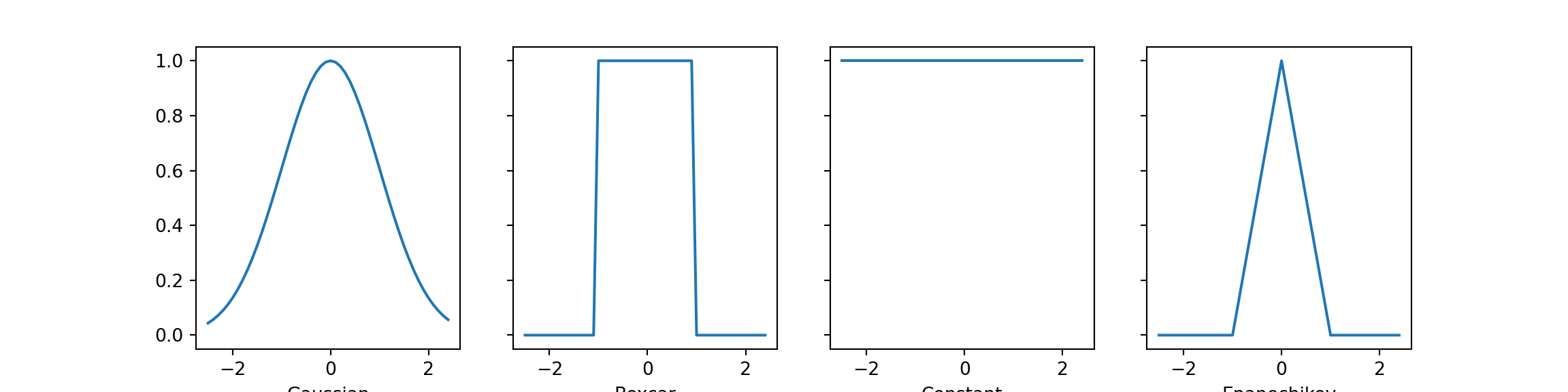
The weights \(\alpha_i\) assign importance to \(y_i\) based on how close \(q = (x_1, x_2)\) is to \(x^{(i)}\). Common kernel choices and their formulas are summarized below:
Here, \(h\) is a bandwidth parameter controlling the width of the kernel, and \(\mathbb{I}\) is the indicator function. Code for the kernels is given below.
import numpy as npimport matplotlib.pyplot as plt# Define some kernels for attention poolingdef gaussian(x): return np.exp(-x**2/2)def boxcar(x): return np.abs(x) <1.0def constant(x): return1.0+0* x # noqa: E741def epanechikov(x): return np.maximum(1- np.abs(x), np.zeros_like(x))
Each of these kernels represents a different way of weighting information based on similarity or distance. In neural networks, this translates to learning how to attend to different parts of the input sequence, but with the flexibility to learn much more complex patterns than these simple mathematical functions.
Now, lets plot the true value of the function and the kernel smoothed value.
Kernel Smoothing
import numpy as npimport matplotlib.pyplot as pyplotprint("DEBUG: Imported pyplot")## DEBUG: Imported pyplot# print(dir())def gaussian_kernel_smoothing(X1, X2, x1_train, x2_train, y_train, bandwidth=0.1):# Get the shape of the grid shape = X1.shape# Flatten the grid points for easier computation X1_flat = X1.flatten() X2_flat = X2.flatten()# Initialize predictions array y_pred_flat = np.zeros(len(X1_flat))# For each test point, compute weighted average using Gaussian kernelfor i inrange(len(X1_flat)): test_x1, test_x2 = X1_flat[i], X2_flat[i]# Compute distances from test point to all training points distances_squared = (x1_train - test_x1)**2+ (x2_train - test_x2)**2# Compute Gaussian weights weights = np.exp(-distances_squared / (2* bandwidth**2))# Compute weighted average (kernel smoothing prediction)if np.sum(weights) >0: y_pred_flat[i] = np.sum(weights * y_train) / np.sum(weights)else: y_pred_flat[i] =0# fallback if all weights are zero# Reshape back to grid shape y_pred = y_pred_flat.reshape(shape)return y_preddef gaussian(x):return np.exp(-x**2/2)# Generate grid data for x1 and x2 (test data)x1 = np.linspace(0, 1, 100)x2 = np.linspace(0, 1, 100)# Now compute the grid of x1 and x2 valuesX1, X2 = np.meshgrid(x1, x2)# Generate training datax1_train = np.random.uniform(0, 1, 100)x2_train = np.random.uniform(0, 1, 100)y_train = np.sin(2* np.pi * x1_train) + x2_train*x2_train + np.random.normal(0, 0.1, 100)# Test the function with the existing datay_pred = gaussian_kernel_smoothing(X1, X2, x1_train, x2_train, y_train, bandwidth=0.1)# Plot comparison between true function and kernel smoothing predictionfig, axes = pyplot.subplots(1, 3, figsize=(15, 5))# True function (without noise for cleaner visualization)y_true = np.sin(2* np.pi * X1) + X2*X2# Plot 1: True functionim1 = axes[0].contourf(X1, X2, y_true, levels=20, cmap='viridis')axes[0].scatter(x1_train, x2_train, c='red', marker='x', s=30, alpha=0.7)axes[0].set_title('True Function')axes[0].set_xlabel('x1')axes[0].set_ylabel('x2')pyplot.colorbar(im1, ax=axes[0])## <matplotlib.colorbar.Colorbar object at 0x136485dc0># Plot 2: Kernel smoothing predictionim2 = axes[1].contourf(X1, X2, y_pred, levels=20, cmap='viridis')axes[1].scatter(x1_train, x2_train, c='red', marker='x', s=30, alpha=0.7)axes[1].set_title('Gaussian Kernel Smoothing')axes[1].set_xlabel('x1')axes[1].set_ylabel('x2')pyplot.colorbar(im2, ax=axes[1])## <matplotlib.colorbar.Colorbar object at 0x13651df40># Plot 3: Difference (error)diff = y_true - y_predim3 = axes[2].contourf(X1, X2, diff, levels=20, cmap='RdBu_r')axes[2].scatter(x1_train, x2_train, c='black', marker='x', s=30, alpha=0.7)axes[2].set_title('Error (True - Predicted)')axes[2].set_xlabel('x1')axes[2].set_ylabel('x2')plt.colorbar(im3, ax=axes[2])## <matplotlib.colorbar.Colorbar object at 0x13658bf20>plt.tight_layout()plt.show()
Kernel Smoothing using Gaussian Kernel
We can see that a relatively simple concept of calculating a prediction by averaging the values of the training data, weighted by the kernel function, can be used to estimate the value of the function at a new point rather well. Clearly, the model is not performing well in the regions where we do not have training data, but it is still able to capture the general shape of the function.
Attention over a sequence of words
This elegant mechanism liberates the model from the tyranny of sequential processing. It can look at an entire sequence at once, effortlessly handling text of any length, drawing connections between distant words in a text, and processing information in parallel, making it incredibly efficient to train.
There are two variations of attention that are particularly important: Cross-attention allows a model to weigh the importance of words in an input sequence (like an encoder’s output) when generating a new output sequence (in the decoder). Self-attention allows a model to weigh the importance of different words within a single input sequence.
In self-attention, queries, keys, and values all come from the same sequence. This allows each position in the sequence to attend to all other positions, creating rich representations that capture the complex web of relationships within a single piece of text. When you read a sentence like “The trophy would not fit in the brown suitcase because it was too big,” self-attention helps the model understand that “it” most likely refers to the trophy, not the suitcase, by considering the relationships between all the words simultaneously.
Let’s now consider a sequence of words (or tokens), where each word is represented as a vector (embedding) \[
H = [h_1, h_2, \ldots, h_n] \in \mathbb{R}^{n \times d}.
\] Here \(n\) is the length of our sequence to be analyzed. It can be a sentence, a paragraph, a document. In case of self-attention, the trio of \(Q, K, V\) are all projections of the same input sequence \(H\)
\[
Q = H W_Q, \quad K = H W_K, \quad V = H W_V.
\] The projections are done by multiplying the input sequence \(H\) by a learnable parameter matrix \(W_Q, W_K, W_V \in \mathbb{R}^{d \times d_k}\). Thus the resulting \(Q, K, V\) are of dimension \(n \times d_k\). Now, we can calculate the unnormalized attention scores as: \[
s_{ij} = \frac{q_i^T k_j}{\sqrt{d_k}}, \quad i,j = 1, \ldots, n.
\] where \(q_i\) is the \(i\)-th row of \(Q\), \(k_j\) is the \(j\)-th row of \(K\), and \(d_k\) is the dimension of the key vectors. The attention weights are then obtained by normalizing with the softmax function: \[
\alpha_{ij} = \frac{\exp(s_{ij})}{\sum_{k=1}^n \exp(s_{ik})}.
\] This softmax normalization ensures that attention weights sum to one, creating a proper probability distribution over the input positions. The scaling factor \(1/\sqrt{d_k}\) prevents the dot products from becoming too large, which would push the softmax into regions with extremely small gradients.
The final output is then computed as: \[
o_i = \sum_{j=1}^n \alpha_{ij} v_j.
\] where \(o_i\) is the \(i\)-th row of the output.
Notice that instead of using the Gaussian kernel, as we did before, we simply use the dot product. This makes computation much faster and more efficient, while still being able to capture the similarity between the words. Matrix-matrix product operation is implemented in all major deep learning libraries. It is differentiable, ensuring that its gradient remains stable, which is crucial for model training. Alternative attention mechanisms exist—notably non-differentiable variants trained via reinforcement learning (Mnih et al. 2014)—but their training complexity has led most researchers to adopt the differentiable framework we present here.
The dot product naturally measures the alignment or “similarity” between two vectors. A larger dot product implies the vectors are pointing in a similar direction. When combined with the scaling factor and the softmax function, this simple calculation has proven to be a highly effective way to determine which tokens are most relevant to each other for language processing tasks. It provides a good signal for “unnormalized alignment” before being converted into a probability distribution. In fact, the dot product is a special case of a kernel function. For normalized vectors, the dot product is equivalent to the cosine similarity. \[
Q_i \cdot K_j = \cos(\theta_{ij})
\] where \(\theta_{ij}\) is the angle between the \(i\)-th and \(j\)-th vectors. It is proportional to \[
\cos(\theta_{ij}) \propto -\|Q_i - K_j\|^2
\] up to constants. In fact, if \(Q\) and \(K\) are normalized and \(\sigma\) is tuned, the Gaussian kernel becomes almost equivalent to a softmax over dot products. For the specific tasks that attention methods excel at, more complex kernels like the Gaussian kernel haven’t demonstrated a consistent or significant enough improvement in performance to justify their increased computational overhead.
Now instead of calculating norms, we calculate the dot product and instead of having a bandwidth parameter that needs to be tuned, we have projection matrices \(W_Q, W_K, W_V\), that are learned during training.
For example, let’s consider the following sentence:
“The cat sat on the mat”
A trained attention model will produce a matrix of attention weights, where each row corresponds to a word in the sentence, and each column corresponds to a word in the sentence. The attention weights are then used to compute the output embeddings
Attention weights for the sentence “The cat sat on the mat”
In examining key attention patterns and linguistic insights, we observe several notable relationships. Firstly, the determiner-noun relationship is exemplified by the word “The” showing the strongest attention to its corresponding noun “cat,” with an attention weight of 0.70. This highlights the model’s capability to capture syntactic dependencies between determiners and their head nouns.
Next, we consider subject-predicate dependencies. The verb “sat” demonstrates a strong attention to its subject “cat,” with a weight of 0.60, indicating that the model effectively learns subject-verb relationships, which are crucial for semantic understanding. Conversely, the attention from “cat” to “sat” is weaker, with a weight of 0.20, illustrating asymmetric attention patterns.
In terms of prepositional phrase structure, the preposition “on” shows a strong attention to its object “mat,” with a weight of 0.50, effectively capturing the prepositional phrase structure. The object “mat” reciprocates with moderate attention to its governing preposition “on,” with a weight of 0.25.
Finally, self-attention patterns reveal that diagonal elements exhibit varying self-attention weights. Notably, “mat” and “cat” display higher self-attention weights of 0.50 and 0.40, respectively, suggesting their importance as content words in contrast to function words.
Cross-attention is a variant of attention where the queries come from one sequence (typically the decoder), while the keys and values come from a different sequence (typically the encoder). This is the mechanism that allows translation models to “look back” at the source sentence while generating each word. The unnormalized score \(s_{ij}\) is calculated as: \[
s_{ij} = \frac{q_i^T k_j}{\sqrt{d_k}}, \quad i = 1, \ldots, n_{\text{decoder}}, \quad j = 1, \ldots, n_{\text{encoder}},
\] where \(q_i\) comes from the decoder’s representation and \(k_j\) comes from the encoder’s representation. This measures how important the \(j\)-th word in the source sequence is for generating the \(i\)-th word in the target sequence. The attention weights are then normalized by the softmax function: \[
\alpha_{ij} = \frac{\exp(s_{ij})}{\sum_{k=1}^{n_{\text{encoder}}} \exp(s_{ik})}.
\]
23.9 Cross-attention for Translation
In the context of sequence-to-sequence models, one of the key challenges is effectively aligning words and phrases between the source and target languages. This alignment is crucial for ensuring that the translated output maintains the intended meaning and grammatical structure of the original text. Cross-attention mechanisms address this problem by allowing the model to focus on relevant parts of the source sequence when generating each word in the target sequence. This selective focus helps in capturing the nuances of translation, such as word order differences and syntactic variations, which are common in multilingual contexts.
The sequence-to-sequence is probably the most commonly used application of language models. Examples include machine translation, text summarization, and text generation from a prompt, question-answering, and chatbots.
Consider a problem of translating ``The cat sleeps’’ into French. The encoder will produce a sequence of embeddings for the source sentence, and the decoder will produce a sequence of embeddings for the target sentence. The cross-attention mechanism will use English embeddings as keys and values, and French embeddings as queries. The attention weights will be calculated as shown in Figure 23.1.
Figure 23.1: Cross-attention matrix for the translation of “The cat sleeps” into French
The rows are queries, and are represented by the French decoder tokens [“Le”, “chat”, “dort”]. Columns, which serve as Keys and Values, are represented by the English encoder tokens [“The”, “cat”, “sleeps”, “”]. The attention matrix is non-square, with dimensions of 3×4, corresponding to the decoder length and encoder length, respectively.
Key Attention Patterns:
Word-by-Word Alignment:
The French word “Le” aligns with the English word “The” with an attention weight of 0.85, indicating that determiners align across languages.
The French word “chat” aligns with the English word “cat” with an attention weight of 0.80, demonstrating a direct semantic translation.
The French word “dort” aligns with the English word “sleeps” with an attention weight of 0.75, showing that verb concepts align.
Cross-Linguistic Dependencies:
Each French word primarily focuses on its English equivalent, with minimal attention given to unrelated source words. This pattern reflects the model’s ability to learn translation alignments.
Multi-Head Attention: Parallel Perspectives
While single-head attention captures one type of relationship between positions, real language exhibits multiple types of dependencies simultaneously. Consider the sentence “The student who studied hard passed the exam.” We might want to simultaneously track: - Syntactic relationships (subject-verb agreement between “student” and “passed”) - Semantic relationships (causal connection between “studied hard” and “passed”)
- Coreference relationships (resolution of “who” to “student”)
Multi-head attention addresses this by computing multiple attention functions in parallel, each potentially specializing in different types of relationships:
The projection matrices \(\mathbf{W}_Q^i, \mathbf{W}_K^i, \mathbf{W}_V^i\) are typically chosen so that \(d_k = d_v = d_{\text{model}}/h\), keeping the total computational cost comparable to single-head attention with full dimensionality.
The final linear projection \(\mathbf{W}_O\) allows the model to learn how to combine information from different heads. This design enables the model to attend to different representation subspaces simultaneously, capturing multiple types of relationships that might be difficult for a single attention head to model.
Positional Information in Attention
Unlike recurrent networks that process sequences step by step, attention mechanisms are permutation-invariant—they produce the same output regardless of input order. While this property enables parallelization, it discards crucial positional information essential for language understanding.
The Transformer architecture addresses this through positional encodings that are added to the input embeddings before attention computation. The original formulation uses sinusoidal encodings:
where \(\text{pos}\) is the position and \(i\) is the dimension. This encoding has several desirable properties: - Different frequencies allow the model to distinguish positions at different scales - The sinusoidal structure enables the model to extrapolate to longer sequences than seen during training - The encoding is deterministic and doesn’t require additional parameters
Alternative approaches include learned positional embeddings or relative position encodings that explicitly model the distance between positions rather than their absolute locations.
Computational Efficiency and Practical Considerations
The quadratic complexity of self-attention has motivated numerous efficiency improvements. Sparse attention patterns restrict which positions can attend to each other, reducing complexity while maintaining representational power. For example, local attention only allows positions to attend within a fixed window, while strided attention creates dilated patterns that maintain long-range connectivity.
Linear attention approximates the full attention matrix using low-rank decompositions or kernel approximations, reducing complexity to \(O(nd)\). While these methods sacrifice some representational capacity, they enable processing of much longer sequences.
Gradient accumulation and mixed precision training have become standard practices for training large attention-based models. The former allows simulation of larger batch sizes on limited hardware, while the latter uses 16-bit floating point for most operations while maintaining 32-bit precision for critical computations.
From Attention to Modern Language Models
The attention mechanism’s success stems from its ability to create flexible, context-dependent representations while maintaining computational efficiency through parallelization. This foundation enabled the development of increasingly sophisticated architectures:
BERT uses bidirectional self-attention encoders for contextual understanding
GPT employs causal self-attention decoders for autoregressive generation
T5 combines encoder-decoder architectures for sequence-to-sequence tasks
Each of these models builds on the query-key-value framework, demonstrating its fundamental importance to modern NLP. The attention mechanism’s interpretability—we can visualize attention weights to understand what the model focuses on—provides valuable insights into model behavior and has influenced model design and debugging practices.
The evolution from fixed word embeddings to dynamic, contextual representations through attention mechanisms represents one of the most significant advances in computational linguistics. By enabling models to adaptively focus on relevant information, attention has unlocked capabilities that seemed impossible just a decade ago.
23.10 Transformer Architecture
The Transformer represents a fundamental shift in how we approach neural network architectures for sequential data. Introduced in the seminal paper “Attention is All You Need” by Vaswani et al. (2023) in 2017, the Transformer has since become the backbone of virtually every state-of-the-art language model, from OpenAI’s GPT series to Google’s Gemini and Meta’s Llama. Beyond text generation, Transformers have proven remarkably versatile, finding applications in audio generation, image recognition, protein structure prediction, and even game playing.
At its core, text-generative Transformer models operate on a deceptively simple principle: next-word prediction. Given a text prompt from the user, the model’s fundamental task is to determine the most probable next word that should follow the input. This seemingly straightforward objective, when scaled to billions of parameters and trained on vast text corpora, gives rise to emergent capabilities that often surprise even their creators.
The first step in the Transformers is the self-attention mechanism, which allows them to process entire sequences simultaneously rather than sequentially. This parallel processing capability not only enables more efficient training on modern hardware but also allows the model to capture long-range dependencies more effectively than previous architectures like recurrent neural networks.
While modern language models like GPT-4 contain hundreds of billions of parameters, the fundamental architectural principles can be understood through smaller models like GPT-2. The GPT-2 small model, with its 124 million parameters, shares the same core components and principles found in today’s most powerful models, making it an ideal vehicle for understanding the underlying mechanics.
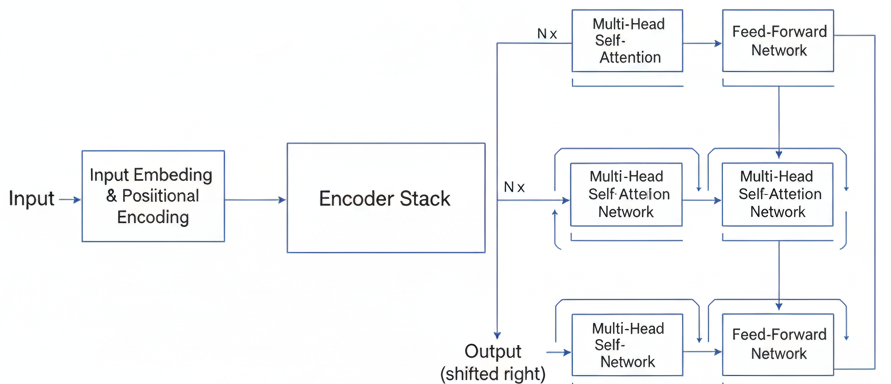
The figure below shows the schematic representation of a Transformer architecture.
Transformer Architecture
Transformer consists of four fundamental components that work in concert to transform raw text into meaningful predictions. The first step involves converting text to numbers (Tokenizer, Embedding Layer, Positional Encoding). The second step involves the Self-Attention mechanism. The third step involves the Multi-Layer Perceptron (MLP). The final step involves the Output Probabilities. We have covered the first two steps in the previous section. Now we will cover the third step, the Multi-Layer Perceptron. Following the attention mechanism, each token’s representation passes through a position-wise feedforward network. The MLP serves a different purpose than attention: while attention routes information between tokens, the MLP transforms each token’s representation independently.
The MLP consists of two linear transformations with a GELU activation function:
The first transformation expands the dimensionality, allowing the model to use a higher-dimensional space for computation before projecting back to the original size. This expansion provides the representational capacity needed for complex transformations while maintaining consistent dimensions across layers.
After processing through all Transformer blocks, the final step converts the rich contextual representations back into predictions over the vocabulary. This involves two key operations. First, The final layer representations are projected into vocabulary space using a linear transformation:
This produces a vector of \(|V|\) values (one for each token in the vocabulary) called logits, representing the model’s raw preferences for each possible next token.
The logits are converted into a probability distribution using the softmax function:
This creates a valid probability distribution where all values sum to 1, allowing us to sample the next token based on the model’s learned preferences.
While the three main components form the core of the Transformer, several additional mechanisms enhance stability and performance:
Layer Normalization
Applied twice in each Transformer block (before attention and before the MLP), layer normalization stabilizes training by normalizing activations across the feature dimension:
where \(\mu\) and \(\sigma\) are the mean and standard deviation computed across the feature dimension, and \(\gamma\) and \(\beta\) are learned scaling and shifting parameters.
Residual Connections
Residual connections create shortcuts that allow gradients to flow directly through the network during training:
These connections are crucial for training deep networks, preventing the vanishing gradient problem that would otherwise make it difficult to update parameters in early layers.
Dropout
During training, dropout randomly zeros out a fraction of neuron activations, preventing overfitting and encouraging the model to learn more robust representations. Dropout is typically disabled during inference.
Computational Complexity and Scalability
The Transformer architecture’s quadratic complexity with respect to sequence length (\(O(n^2)\) for self-attention) has motivated numerous efficiency improvements. However, this complexity enables the model’s remarkable ability to capture long-range dependencies that simpler architectures cannot handle effectively.
Modern implementations leverage optimizations like: - Gradient checkpointing to trade computation for memory - Mixed precision training using 16-bit floating point - Efficient attention implementations that minimize memory usage
The Transformer’s success stems from its elegant balance of expressivity and computational efficiency. By enabling parallel processing while maintaining the ability to model complex dependencies, it has become the foundation for the current generation of large language models that are reshaping our interaction with artificial intelligence.
The complete Transformer architecture consists of two main components working in harmony. The encoder stack processes input sequences through multiple layers of multi-head self-attention and position-wise feedforward networks, enhanced with residual connections and layer normalization that help stabilize training. The decoder stack uses masked multi-head self-attention to prevent the model from “cheating” by looking at future tokens during training.
This architecture enabled the development of three distinct families of models, each optimized for different types of tasks. Encoder-only models like BERT excel at understanding tasks such as classification, question answering, and sentiment analysis. They can see the entire input at once, making them particularly good at tasks where understanding context from both directions matters.
Decoder-only models like GPT are particularly good at generation tasks, producing coherent, contextually appropriate text. These models are trained to predict the next token given all the previous tokens in a sequence, which might seem simple but turns out to be incredibly powerful for natural text generation.
Encoder-decoder models like T5 bridge both worlds, excelling at sequence-to-sequence tasks like translation and summarization. The text-to-text approach treats all tasks as text generation problems. Need to translate from English to French? The model learns to generate French text given English input. Want to answer a question? The model generates an answer given a question and context.
23.11 Pretraining at Scale: BERT and Beyond
The availability of powerful architectures raised a crucial question: how can we best leverage unlabeled text to learn general-purpose representations? BERT (Bidirectional Encoder Representations from Transformers) introduced a pretraining framework that has become the foundation for modern NLP.
BERT’s key innovation was masked language modeling (MLM), where 15% of tokens are selected for prediction. For each selected token, 80% are replaced with [MASK], 10% with random tokens, and 10% left unchanged. This prevents the model from simply learning to copy tokens when they’re not masked. The loss function only considers predictions for masked positions:
BERT combines MLM with next sentence prediction (NSP), which trains the model to understand relationships between sentence pairs. Training examples contain 50% consecutive sentences and 50% randomly paired sentences. The input representation concatenates both sentences with special tokens and segment embeddings to distinguish between them.
The scale of BERT pretraining represents a quantum leap from earlier approaches. The original BERT models were trained on a combination of BookCorpus (800 million words from over 11,000 books) and English Wikipedia (2,500 million words). This massive dataset enables the model to see diverse writing styles, topics, and linguistic phenomena. The preprocessing pipeline removes duplicate paragraphs, filters very short or very long sentences, and maintains document boundaries to ensure coherent sentence pairs for NSP.
BERT Architecture and Training Details
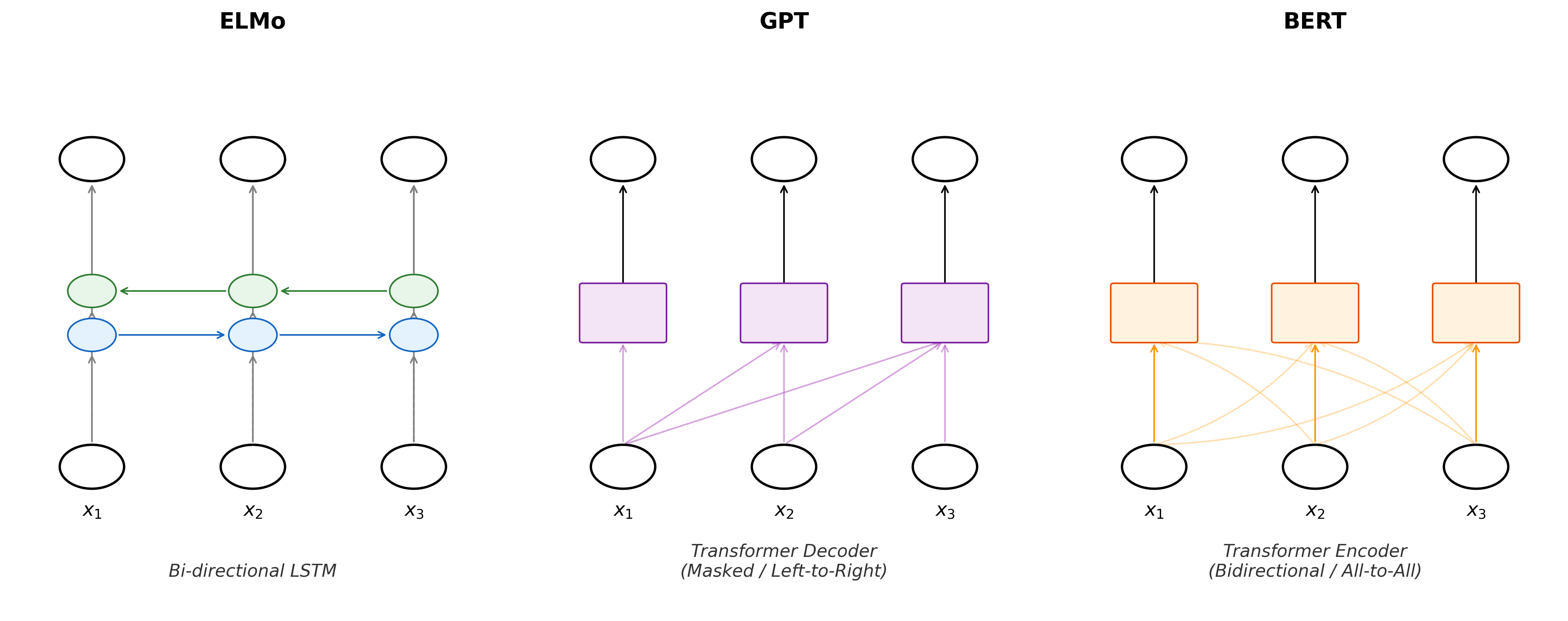
To understand BERT’s architectural significance, it’s helpful to compare it with its predecessors ELMo and GPT, which represent different approaches to contextual representation learning:
Figure 23.2: Comparison of ELMo, GPT, and BERT architectures
ELMo uses bidirectional LSTMs with task-specific architectures, requiring custom model design for each application. GPT employs a unidirectional Transformer decoder that processes text left-to-right, making it task-agnostic but unable to see future context. BERT combines the best of both: bidirectional context understanding through Transformer encoders with minimal task-specific modifications (just an output layer). BERT comes in two main configurations that balance model capacity with computational requirements:
BERT configurations and parameters
Model
Transformer Layers
Hidden Dimensions
Attention Heads
Parameters
BERT-Base
12
768
12
110M
BERT-Large
24
1024
16
340M
Both models use a vocabulary of 30,000 WordPiece tokens, learned using a data-driven tokenization algorithm similar to BPE. The maximum sequence length is 512 tokens, though most pretraining uses sequences of 128 tokens to improve efficiency, with only the final 10% of training using full-length sequences.
The pretraining procedure involves several techniques to stabilize and accelerate training:
Warm-up Learning Rate: The learning rate increases linearly for the first 10,000 steps to \(10^{-4}\), then decreases linearly. This warm-up prevents large gradients early in training when the model is randomly initialized.
Gradient Accumulation: To simulate larger batch sizes on limited hardware, gradients are accumulated over multiple forward passes before updating weights. BERT uses an effective batch size of 256 sequences.
Mixed Precision Training: Using 16-bit floating point for most computations while maintaining 32-bit master weights speeds up training significantly on modern GPUs.
Data Preparation for BERT Pretraining
The data preparation pipeline for BERT is surprisingly complex. Starting with raw text, the process involves:
graph LR
A[Raw Text] --> B[Document Segmentation]
B --> C[Sentence Segmentation]
C --> D[WordPiece Tokenization]
D --> E[Creating Training Examples]
E --> F[Creating TFRecord Files]
In the document segmentation stage, text is split into documents, maintaining natural boundaries. For books, this means chapter boundaries; for Wikipedia, article boundaries. The next stage is sentence segmentation, where each document is split into sentences using heuristic rules. Typically, this involves identifying periods followed by whitespace and capital letters, while accounting for exceptions such as abbreviations.
Following sentence segmentation, the text undergoes WordPiece tokenization. This process uses a learned WordPiece vocabulary to break text into subword units, ensuring that unknown words can be represented as sequences of known subwords. Special handling is applied to mark the beginning of words.
Once tokenized, the data is organized into training examples. For each example, a target sequence length is sampled from a geometric distribution to introduce variability. Sentences are packed together until the target length is reached. For the next sentence prediction (NSP) task, half of the examples use the actual next segment, while the other half use a randomly selected segment. Masked language modeling (MLM) is applied by masking 15% of tokens, following the 80/10/10 strategy: 80% of the time the token is replaced with [MASK], 10% with a random token, and 10% left unchanged. Special tokens such as [CLS] at the beginning and [SEP] between segments are added, and segment embeddings are created (0 for the first segment, 1 for the second). Sequences are padded to a fixed length using [PAD] tokens.
Finally, the prepared examples are serialized into TFRecord files for efficient input/output during training. Examples are grouped by sequence length to minimize the amount of padding required.
The democratization of pretraining through libraries like Hugging Face Transformers has made it possible for smaller organizations to leverage these powerful techniques, either by fine-tuning existing models or pretraining specialized models for their domains.
23.12 Transfer Learning and Downstream Applications
The power of pretrained models lies in their transferability. The landscape of NLP applications can be broadly categorized into two fundamental types based on their input structure and prediction granularity. Sequence-level tasks operate on entire text sequences, producing a single output per input sequence or sequence pair. Token-level tasks make predictions for individual tokens within sequences, such as named entity recognition that identifies person names, locations, and organizations.
For sentiment analysis, we add a linear layer on top of the [CLS] token representation and fine-tune on labeled data. Popular datasets include IMDb movie reviews (50K examples) and Stanford Sentiment Treebank (11,855 sentences). Modern models can capture nuanced semantic relationships that traditional lexicon-based approaches miss. For instance, the phrase “not bad” expresses mild approval despite containing the negative word “bad,” while “insanely good” uses typically negative intensity (“insanely”) to convey strong positive sentiment. Fine-tuning typically requires only 2-4 epochs, demonstrating the effectiveness of transfer learning.
Natural language inference (NLI) determines logical relationships between premise and hypothesis sentences. The Stanford Natural Language Inference corpus contains 570,000 sentence pairs labeled as entailment, contradiction, or neutral. For BERT-based NLI, we concatenate premise and hypothesis with [SEP] tokens and classify using the [CLS] representation. This allows the model to leverage cross-attention to identify which words and phrases support or contradict the proposed logical relationship.
Token-level tasks like named entity recognition classify each token independently. Common datasets include CoNLL-2003 (English and German entities) and OntoNotes 5.0 (18 entity types). The BIO tagging scheme marks entity boundaries: B-PER for beginning of person names, I-PER for inside, and O for outside any entity. For example, in “Apple Inc. was founded by Steve Jobs”, “Apple” would be tagged B-ORG, “Inc.” as I-ORG, “Steve” as B-PER, and “Jobs” as I-PER.
Question answering presents unique challenges. The SQuAD dataset contains 100,000+ questions where answers are text spans from Wikipedia articles. BERT approaches this by predicting start and end positions independently, with the final answer span selected to maximize the product of start and end probabilities subject to length constraints. For a question like “Who founded Apple?”, the model identifies the span “Steve Jobs” in the context passage.
23.13 Model Compression and Efficiency
While large pretrained models achieve impressive performance, their computational requirements limit deployment. Knowledge distillation trains a small “student” model to mimic a large “teacher” model through a combined loss:
DistilBERT achieves 97% of BERT’s performance with 40% fewer parameters and 60% faster inference. Quantization reduces numerical precision from 32-bit to 8-bit or even lower, while pruning removes connections below a magnitude threshold. These techniques can reduce model size by an order of magnitude with minimal performance degradation.
23.14 Theoretical Perspectives and Future Directions
The success of language models connects to several theoretical frameworks. Transformers are universal approximators for sequence-to-sequence functions—given sufficient capacity, they can approximate any continuous function to arbitrary precision. The self-attention mechanism provides an inductive bias well-suited to capturing long-range dependencies.
Despite having hundreds of millions of parameters, these models generalize remarkably well. This connects to implicit regularization in overparameterized models, where gradient descent dynamics bias toward solutions with good generalization properties. Language models automatically learn hierarchical features: early layers capture syntax and morphology, middle layers semantic relationships, and later layers task-specific abstractions.
Yet significant challenges remain. Models struggle with compositional generalization—understanding “red car” and “blue house” doesn’t guarantee understanding “red house” if that combination is rare in training. The sample efficiency gap is stark: a child masters basic grammar from thousands of examples, while BERT requires billions—suggesting fundamental differences between neural network optimization and human language acquisition.
Interpretability poses ongoing challenges. While attention visualizations provide some insights, we lack principled methods for understanding distributed representations across hundreds of layers and attention heads. Future directions include multimodal understanding (integrating text with vision and speech), more efficient architectures that maintain performance while reducing computational requirements, and developing theoretical frameworks to predict and understand model behavior.
23.15 Conclusion
The journey from symbolic manipulation to neural language understanding represents one of the great success stories of modern artificial intelligence. By reconceptualizing language as geometry in high-dimensional spaces, leveraging self-supervision at scale, and developing powerful architectural innovations like transformers, the field has achieved capabilities that seemed like science fiction just a decade ago.
The mathematical frameworks developed—from distributional semantics to attention mechanisms—provide not just engineering tools but lenses through which to examine fundamental questions about meaning and understanding. As these systems become more capable and widely deployed, understanding their theoretical foundations, practical limitations, and societal implications becomes ever more critical.
The techniques discussed in this chapter—word embeddings, contextual representations, pretraining, and fine-tuning—form the foundation of modern NLP systems. Yet despite impressive engineering achievements, we’ve only begun to scratch the surface of true language understanding. The rapid progress offers both tremendous opportunities and sobering responsibilities. The most exciting chapters in this story are yet to be written.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. “Neural Machine Translation by Jointly Learning to Align and Translate.” arXiv. https://arxiv.org/abs/1409.0473.
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Efficient Estimation of Word Representations in Vector Space.” arXiv. https://arxiv.org/abs/1301.3781.
Mnih, Volodymyr, Nicolas Heess, Alex Graves, and Koray Kavukcuoglu. 2014. “Recurrent Models of Visual Attention.”Advances in Neural Information Processing Systems 27: 2204–12.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. “Attention Is All You Need.” arXiv. https://arxiv.org/abs/1706.03762.